<< ตรวจสอบไวยากรณ์ | # >>
- ดาวน์โหลด CT414_1_54_v2
- รองรับการประกาศตัวแปร (dim) และสตรัก (struct)
- ฟ้องการประกาศตัวแปรซ้ำ, ฟ้องการประกาศฟิวด์ซ้ำ และฟ้องการกำหนดไทป์ที่ยังไม่ได้ประกาศ
- ดาวน์โหลด CT414_1_54_v3
- รองรับการให้ไทป์ (Type) ทั้งแบบธรรมดา (int, float, string) และแบบสตรัก (struct)
*** ทดสอบด้วยการกำหนดจุด debug ณ เมธอด T แล้ว debug โดยใช้ช่อง Watches พิมพ์ varList และ structList
- ดาวน์โหลด CT414_1_54_v4
- ทำงาน comment (ดูไฟล์ Lexical.java ส่วนการตัด comment) สำหรับ Parser ได้แล้ว
- เปลี่ยนชื่อตัวแปร local บางชื่อ (ไม่มีผลใดๆต่อ version ที่ผ่านมา แค่เปลี่ยนชื่อเฉยๆ) ได้แก่ fieldList เป็น fields
- ระบุค่าแอตทริบิวต์ name ของคลาส Symbol เป็น "_unknown"
- ระบุค่าแอตทริบิวต์ codeName และ codeType ของคลาส Token เป็น -1 ทั้งคู่
- ฟ้องการเรียกใช้งานตัวแปรแบบปกติและแบบสตรัก
ผมต้องไปรายงานตัวทางทหารกับอำเภอแล้วครับ เสียใจด้วยที่เขียนให้ได้เท่านี้ พยายามดูโค้ดแล้วสร้างความเข้าใจทีละขั้นตอน เชื่อมั่นและมีไฟ สำหรับ source code ที่ให้ ให้ถือว่าเป็นแนวทางนะครับ อย่าได้ยึดติดว่าต้องเขียนอย่างนี้อย่างนั้นเสมอไป เขียนไปตามขั้นตอนและอัลกอลิทึมของตัวเองให้เข้าใจก่อนเป็นดีที่สุด สวัสดีครับเพื่อนๆ
วันศุกร์ที่ 28 ตุลาคม พ.ศ. 2554
วันอังคารที่ 25 ตุลาคม พ.ศ. 2554
ตรวจสอบไวยากรณ์
<< ตัดคำ | การให้ความหมาย >>
ตัดคำสำเร็จแล้ว ผลลัพธ์ที่ได้ต้องมี token stream และ symbol table สองอย่างนี้เป็นที่ถกเถียงกันเหลือเกินว่า อย่างไหนจำเป็น อย่างไหนไม่จำเป็น แท้จริงก็จำเป็นทั้งคู่ หากว่ากันตามตำราที่อาจารย์ใช้สอนแล้ว หน้าที่ของทั้งสองมีดังนี้ครับ
- token stream สำหรับ token ทั้งหมดที่ตัดได้จาก source code เรียงร้อยกันไปเรื่อยๆ
- symbol table สำหรับ token ที่ซ้ำกันเก็บแค่อันครั้งเดียวและอยู่ในรูปแบบตัวเลขโค้ด (ตั้งเอาเอง)
ดังตัวอย่าง สมมติ source code ดังนี้
A() {
}
main() {
}
ก็จะได้ token stream ดังนี้
- กำหนดให้เครื่องหมาย [ และ ] แทนหนึ่ง token
[ "A" : "identifier" ][ "(" : "separator" ][ ")" : "separator" ]
[ "{" : "separator" ][ "}" : "separator" ]
[ "main" : "keyword" ][ "(" : "separator" ][ ")" : "separator" ]
[ "{" : "separator" ][ "}" : "separator" ]
และมี symbol table ดังนี้
[ 0 : "A" : "identifier" ][ 1 : "(" : "separator" ][ 2 : ")" : "separator" ]
[ 3 : "{" : "separator" ][ 4 : "}" : "separator" ][ 5 : "main" : "keyword" ]
โดยปกติแล้ว parser หรือเรียกกว่า "การแปล" จะมีสองขั้นตอนสำคัญคือ
1. ตรวจสอบไวยากรณ์ (syntax)
2. การให้ความหมาย (semantic)
เพราะเวลาจวนตัวผมแล้ว ดังนั้นให้เพื่อนดาวน์โหลด net beans project ชื่อ CT414_1_54_v1 ต่อไปนี้
- ดาวน์โหลด CT414_1_54_v1
- ภายในจะมี folder ชื่อ CT414_1_54 ให้ใช้ NetBeans IDE (ของผมคือ v 6.9.1) เปิดขึ้นมา
- ใน project ดังกล่าว ณ มุมมอง Projects ผมแบ่ง package ออกสองกลุ่ม ได้แก่
- compiler
- problem
package ชื่อ 'compiler' สำหรับงาน compiler ตาม grammar ของเทอม 1/54
package ชื่อ 'problem' สำหรับเฉลยโจทย์ทดสอบที่ผมตั้งถามเพื่อนๆ
เปิด package 'compiler' ออกจะเห็น package ย่อยอีกดังนี้
- lexical
- parsre
- codegen
package ชื่อ 'compiler.lexical' รวบรวมคลาสทั้งหมดที่เกี่ยวข้องกับการตัดคำ (100%)
package ชื่อ 'compiler.parser' รวบรวมคลาสทั้งหมดที่เกี่ยวข้องกับการตรวจสอบไวยากรณ์และให้ความหมาย (50%) ซึ่งขณะนี้สำเร็จเพียงการตรวจสอบไวยากรณ์ ยังเหลือการให้ความหมายที่กำลังเขียนอยู่
package ชื่อ 'compiler.codegen' รวบรวมคลาสทังหมดที่เกี่ยวข้องกับการสร้าง machine code (0%)
ผมใช้ source code ของน้อง "PetPraUMa" ทดสอบแล้ว (ไฟล์ชื่อ SourceCode1.txt) ไม่ปรากฏความผิดพลาดใดๆ ให้เพื่อนๆทดสอบบ้าง โดยมีขั้นตอนคือ
- เปิด package ชื่อ 'compiler' จะพบไฟล์สกุล .java ชื่อ Main และไฟล์สกุล .txt อีกสองไฟล์ ได้แก่ SourceCode.txt และ SourceCode1.txt ไฟล์สกุล .txt ทั้งสองนี้ใช้ทดสอบไวยากรณ์ของ grammar ถูกต้องทุกประการ
- คลิกขวาที่ไฟล์ Main.java เลือก RunFile แล้วสังเกตผลลัพธ์ โชคดีครับ
<< ตัดคำ | การให้ความหมาย >>
ตัดคำสำเร็จแล้ว ผลลัพธ์ที่ได้ต้องมี token stream และ symbol table สองอย่างนี้เป็นที่ถกเถียงกันเหลือเกินว่า อย่างไหนจำเป็น อย่างไหนไม่จำเป็น แท้จริงก็จำเป็นทั้งคู่ หากว่ากันตามตำราที่อาจารย์ใช้สอนแล้ว หน้าที่ของทั้งสองมีดังนี้ครับ
- token stream สำหรับ token ทั้งหมดที่ตัดได้จาก source code เรียงร้อยกันไปเรื่อยๆ
- symbol table สำหรับ token ที่ซ้ำกันเก็บแค่อันครั้งเดียวและอยู่ในรูปแบบตัวเลขโค้ด (ตั้งเอาเอง)
ดังตัวอย่าง สมมติ source code ดังนี้
A() {
}
main() {
}
ก็จะได้ token stream ดังนี้
- กำหนดให้เครื่องหมาย [ และ ] แทนหนึ่ง token
[ "A" : "identifier" ][ "(" : "separator" ][ ")" : "separator" ]
[ "{" : "separator" ][ "}" : "separator" ]
[ "main" : "keyword" ][ "(" : "separator" ][ ")" : "separator" ]
[ "{" : "separator" ][ "}" : "separator" ]
และมี symbol table ดังนี้
[ 0 : "A" : "identifier" ][ 1 : "(" : "separator" ][ 2 : ")" : "separator" ]
[ 3 : "{" : "separator" ][ 4 : "}" : "separator" ][ 5 : "main" : "keyword" ]
โดยปกติแล้ว parser หรือเรียกกว่า "การแปล" จะมีสองขั้นตอนสำคัญคือ
1. ตรวจสอบไวยากรณ์ (syntax)
2. การให้ความหมาย (semantic)
เพราะเวลาจวนตัวผมแล้ว ดังนั้นให้เพื่อนดาวน์โหลด net beans project ชื่อ CT414_1_54_v1 ต่อไปนี้
- ดาวน์โหลด CT414_1_54_v1
- ภายในจะมี folder ชื่อ CT414_1_54 ให้ใช้ NetBeans IDE (ของผมคือ v 6.9.1) เปิดขึ้นมา
- ใน project ดังกล่าว ณ มุมมอง Projects ผมแบ่ง package ออกสองกลุ่ม ได้แก่
- compiler
- problem
package ชื่อ 'compiler' สำหรับงาน compiler ตาม grammar ของเทอม 1/54
package ชื่อ 'problem' สำหรับเฉลยโจทย์ทดสอบที่ผมตั้งถามเพื่อนๆ
เปิด package 'compiler' ออกจะเห็น package ย่อยอีกดังนี้
- lexical
- parsre
- codegen
package ชื่อ 'compiler.lexical' รวบรวมคลาสทั้งหมดที่เกี่ยวข้องกับการตัดคำ (100%)
package ชื่อ 'compiler.parser' รวบรวมคลาสทั้งหมดที่เกี่ยวข้องกับการตรวจสอบไวยากรณ์และให้ความหมาย (50%) ซึ่งขณะนี้สำเร็จเพียงการตรวจสอบไวยากรณ์ ยังเหลือการให้ความหมายที่กำลังเขียนอยู่
package ชื่อ 'compiler.codegen' รวบรวมคลาสทังหมดที่เกี่ยวข้องกับการสร้าง machine code (0%)
ผมใช้ source code ของน้อง "PetPraUMa" ทดสอบแล้ว (ไฟล์ชื่อ SourceCode1.txt) ไม่ปรากฏความผิดพลาดใดๆ ให้เพื่อนๆทดสอบบ้าง โดยมีขั้นตอนคือ
- เปิด package ชื่อ 'compiler' จะพบไฟล์สกุล .java ชื่อ Main และไฟล์สกุล .txt อีกสองไฟล์ ได้แก่ SourceCode.txt และ SourceCode1.txt ไฟล์สกุล .txt ทั้งสองนี้ใช้ทดสอบไวยากรณ์ของ grammar ถูกต้องทุกประการ
- คลิกขวาที่ไฟล์ Main.java เลือก RunFile แล้วสังเกตผลลัพธ์ โชคดีครับ
<< ตัดคำ | การให้ความหมาย >>
ตัดคำ
<< อ่าน EBNF ให้เข้าใจ | ตรวจสอบไวยากรณ์ >>
หลังจากเรื่อง EBNF ก็มาถึงการตัดคำ (Lexical) ตัดคำทำไม? ก็เพื่อแยกแต่ละส่วนของ source code ออกมา แยกมันทำไม? ก็เพื่อนำมาตรวจสอบว่า source code ที่ได้นั้นถูกต้องตามหลักไวยากรณ์ของภาษาหรือไม่ อ่าว~แล้วตัวภาษาเอามาจากไหน จาก grammar ที่นิยามด้วย EBNF นั่นไง พอเข้าใจนะครับ
คำหรือต่อไปนี้จะเรียกว่า token มีหลายประเภท โดยทั่วไปแบ่งออกสี่ประเภท ดังนี้
- keyword บางคนก็เรียกเป็น reserved words ตอนนี้อย่าเพิ่งสงสัยเลยว่ามันต่างกันอย่างไร (ตัวอย่างภาษา C)
- operator ได้แก่ + - * / และอื่นๆ
- separator ได้แก่ { } [ ] ( ) ; , . และอื่นๆ
- identifier หมายถึง ชื่อใดๆที่ตั้งตามหลักการตั้งชื่อหรือข้อตกลงร่วมกันกับอาจารย์ เช่น A myFunction B Phai น้องส้มโอน่ารัก เป็นต้น
สมมุติว่าเรามี source code ดังต่อไปนี้
A() {
}
main() {
}
เมื่อนำมาทำงานตัดคำ จะได้ว่า
keyword : main
operator :
separator : ( ) { }
identifier : A
โจทย์ที่ 2 จงเขียนโปรแกรมตัดคำจากสายสตริง (string) ต่อไปนี้ ให้ได้ผลลัพธ์ดังข้างต้น
- กำหนดคลาสทดสอบชื่อ Test2
- กำหนดตัวแปร local variable ชื่อ sourceCode มีค่า "A() { } main() { }"
class Test2 {
public static void main(String[] args) {
String sourceCode = "A() { } main() { }";
}
}
ทดลองแก้ปัญหาเองก่อน ติดตรงไหน ไวยากรณ์ภาษา Java หรือเปล่า หรือติดที่คิดอัลกอริทึมไม่ออก ค่อยเป็นค่อยไปนะครับ
สำหรับเรื่องตัดคำผมคิดว่าหลายคนคงทำได้แล้ว ดังนั้นหากไม่มี request ให้เสนอวิธีการ (ในแบบของผม) ผมจึงขอข้ามส่วนนี้ไปก่อนนะครับ
<< อ่าน EBNF ให้เข้าใจ | ตรวจสอบไวยากรณ์ >>
หลังจากเรื่อง EBNF ก็มาถึงการตัดคำ (Lexical) ตัดคำทำไม? ก็เพื่อแยกแต่ละส่วนของ source code ออกมา แยกมันทำไม? ก็เพื่อนำมาตรวจสอบว่า source code ที่ได้นั้นถูกต้องตามหลักไวยากรณ์ของภาษาหรือไม่ อ่าว~แล้วตัวภาษาเอามาจากไหน จาก grammar ที่นิยามด้วย EBNF นั่นไง พอเข้าใจนะครับ
คำหรือต่อไปนี้จะเรียกว่า token มีหลายประเภท โดยทั่วไปแบ่งออกสี่ประเภท ดังนี้
- keyword บางคนก็เรียกเป็น reserved words ตอนนี้อย่าเพิ่งสงสัยเลยว่ามันต่างกันอย่างไร (ตัวอย่างภาษา C)
- operator ได้แก่ + - * / และอื่นๆ
- separator ได้แก่ { } [ ] ( ) ; , . และอื่นๆ
- identifier หมายถึง ชื่อใดๆที่ตั้งตามหลักการตั้งชื่อหรือข้อตกลงร่วมกันกับอาจารย์ เช่น A myFunction B Phai น้องส้มโอน่ารัก เป็นต้น
สมมุติว่าเรามี source code ดังต่อไปนี้
A() {
}
main() {
}
เมื่อนำมาทำงานตัดคำ จะได้ว่า
keyword : main
operator :
separator : ( ) { }
identifier : A
โจทย์ที่ 2 จงเขียนโปรแกรมตัดคำจากสายสตริง (string) ต่อไปนี้ ให้ได้ผลลัพธ์ดังข้างต้น
- กำหนดคลาสทดสอบชื่อ Test2
- กำหนดตัวแปร local variable ชื่อ sourceCode มีค่า "A() { } main() { }"
class Test2 {
public static void main(String[] args) {
String sourceCode = "A() { } main() { }";
}
}
ทดลองแก้ปัญหาเองก่อน ติดตรงไหน ไวยากรณ์ภาษา Java หรือเปล่า หรือติดที่คิดอัลกอริทึมไม่ออก ค่อยเป็นค่อยไปนะครับ
สำหรับเรื่องตัดคำผมคิดว่าหลายคนคงทำได้แล้ว ดังนั้นหากไม่มี request ให้เสนอวิธีการ (ในแบบของผม) ผมจึงขอข้ามส่วนนี้ไปก่อนนะครับ
<< อ่าน EBNF ให้เข้าใจ | ตรวจสอบไวยากรณ์ >>
วันจันทร์ที่ 17 ตุลาคม พ.ศ. 2554
อ่าน EBNF ให้เข้าใจ
<< CT414 ภาค 1/54 | ตัดคำ >>
จากตัวอย่างหน้าที่ผ่านมา เราจะแยกคลาสสำหรับทดสอบซึ่งมีเมธอด main ออกมาต่างหาก และเขียนคลาสที่เกี่ยวข้องกับงานทั้งหมดขึ้นมาใหม่ อาจมีเพียงหนึ่งคลาสหรือมากกว่าก็อยู่ที่การออกแบบเป็นหลักครับ เนื่องจากเวลามีน้อย เนื้อหาหน้านี้เราไปทำความรู้จัก EBNF กันก่อนเลย
EBNF ที่เราจะใช้ศึกษาก็คือโจทย์หรือ grammar ที่น้อง "PetPraUMa" ได้โพสต์ไว้ในกระดานข่าวของภาควิชาวิทยาการคอมฯ ให้ดาวน์โหลดมาดูพร้อมกันได้เลย คลิกที่นี่ ดังที่ได้ยกมาบางส่วนด้านล่างนี้
<S> ::= <Sp> main() { <B> }
<Sp> ::= id() { <B> } <Sp>
<Sp> ::= empty_string
<B> ::= <T> <S1>
<T> ::= <ET> dim id <T1> as <T2> ; <T>
<T> ::= empty_string
<ET> ::= extern
<ET> ::= empty_string
<T1> ::= , id <T1>
<T1> ::= empty_string
...เรื่อยไปนะครับ
EBNF ใช้อธิบายโครงสร้างของภาษาหรือที่เรียกว่า "กฏไวยากรณ์" (syntax) ตัวผลิตจะอยู่ทางซ้ายของเครื่องหมาย ::= ส่วนผลิตผลจะอยู่ทางขวาของเครื่องหมาย ::=
EBNF ประกอบด้วย non-terminal และ terminal
นิยามอย่างง่ายที่สุด non-terminal สามารถแบ่งแยกได้เป็น non-terminal หรือ terminal อีกเท่าใดก็ได้
ส่วน terminal ไม่สามารถแบ่งแยกได้อีกแล้ว
ข้อตกลงทั่วไปสำหรับ non-terminal คือต้องเปิดด้วยเครื่องหมาย < และปิดด้วยเครื่องหมาย > เช่น <S> <B> <T> เป็นต้น ทว่าบางทีอาจารย์ท่านก็เขียนเพียงตัวอักษรเฉยๆ แต่อย่างไรก็คือ non-terminal เหมือนกัน ได้แก่ id ซึ่งย่อมาจาก identifier หมายถึงการตั้งชื่อตามกฎการตั้งชื่อตัวแปรของภาษาใดๆ (เรากำหนดเอาเองหรือเลียนแบบภาษา C ก็ได้)
และข้อตกลงทั่วไปสำหรับ terminal คือเป็นตัวอักษรเฉยๆ (ไม่นับ id นะครับ) จาก grammar ข้างต้น เช่น main เครื่องหมาย ( เครื่องหมาย ) เครื่องหมาย { เครื่องหมาย } เหล่านี้เป็นต้น
สุดท้ายสำหรับ empty_string นั้นหมายถึง ว่างเปล่า คือเลือกที่จะไม่ผลิตสิ่งใดหรือกล่าวว่าไม่มีผลิตผลใดๆ
ควรทราบว่า non-terminal อาจเขียนด้วยตัวพิมพ์ใหญ่ เช่น S B T เฉยๆ ไม่มีเครื่องหมาย < และ > ครอบก็เป็นได้ ขึ้นอยู่กับข้อตกลงและตำราที่ใช้เป็นหลัก ส่วน terminal ก็อาจเขียนเป็นตัวพิมพ์เล็กที่อาจมีเครื่องหมาย " และ " ครอบหรือไม่ก็ได้
เราควรอ่าน grammar ให้เป็น คือสามารถนำมันมาสร้างเป็น source code ได้ ตัวอย่าง
<S> ::= <Sp> main() { <B> }
<Sp> ::= id() { <B> } <Sp>
<Sp> ::= empty_string
ในเมื่อ <S> เป็น non-terminal เริ่มต้นของ grammar นี้ ตัวมันสามารถผลิต <Sp> main() { <B> } อย่างนี้จะสร้างเป็น source code อย่างง่ายที่สุดอย่างไร
- กำหนดให้ <Sp> ผลิตได้ empty_string
- กำหนดให้ <B> ผลิตได้ empty_string
ดังนั้น source code จึงเป็น
main() {
}
อ่านถึงตรงนี้พอเข้าใจไหมครับ ทีนี้หากว่า <Sp> ไม่ได้ผลิตเป็น empty_string แต่กลับได้เป็น id() { <B> } <Sp> และกำหนดให้ <B> ผลิตได้ empty_string ดังเดิม เมื่อนั้นหน้าตา source code ก็จะออกมาอย่างนี้
A() {
}
main() {
}
หรือ
A() {
}
myFunction() {
}
main() {
}
หรือทำนองใดๆ พอเข้าใจนะครับ คล้ายกับการประกาศฟังก์ชันแบบ inline ในภาษา C (ฟังก์ชันในภาษา C เรียกการเขียนฟังก์ชันใดๆไว้ก่อน main ว่า inline function มันจะจองหน่วยความจำเท่าที่ตัวฟังก์ชันระบุทันที โดยไม่สนใจว่าฟังก์ชันดังกล่าวจะถูกเรียกใช้หรือไม่ก็ตาม ต่างจากการเขียนฟักง์ชันหลัง main ซึ่งจะจองหน่วยความจำก็ต่อเมื่อเกิดการเรียกใช้ฟังก์ชันจากภายใน main เท่านั้น)
จาก source code ข้างต้นจะเห็นว่าตำแหน่ง id ของตัวผลิต <Sp> สามารถเปลี่ยนเป็นชื่อใดๆก็ได้ตามหลักการตั้งชื่อตัวแปรทั่วไป เช่น A myFunction B Phai น้องส้มโอน่ารัก หรือใดๆตราบเท่าที่เราต้องการ (ต้องอยู่ในข้อตกลงของอาจารย์ด้วยนะ)
สงสัยหรือต้องการให้เพิ่มเติมอย่างไรก็แสดงความเห็น (comment) ด้านล่างนี้ได้เลยครับ หากเข้าใจแล้วให้คลิกลิงค์สู่หน้าต่อไป
<< CT414 ภาค 1/54 | ตัดคำ >>
จากตัวอย่างหน้าที่ผ่านมา เราจะแยกคลาสสำหรับทดสอบซึ่งมีเมธอด main ออกมาต่างหาก และเขียนคลาสที่เกี่ยวข้องกับงานทั้งหมดขึ้นมาใหม่ อาจมีเพียงหนึ่งคลาสหรือมากกว่าก็อยู่ที่การออกแบบเป็นหลักครับ เนื่องจากเวลามีน้อย เนื้อหาหน้านี้เราไปทำความรู้จัก EBNF กันก่อนเลย
EBNF ที่เราจะใช้ศึกษาก็คือโจทย์หรือ grammar ที่น้อง "PetPraUMa" ได้โพสต์ไว้ในกระดานข่าวของภาควิชาวิทยาการคอมฯ ให้ดาวน์โหลดมาดูพร้อมกันได้เลย คลิกที่นี่ ดังที่ได้ยกมาบางส่วนด้านล่างนี้
<S> ::= <Sp> main() { <B> }
<Sp> ::= id() { <B> } <Sp>
<Sp> ::= empty_string
<B> ::= <T> <S1>
<T> ::= <ET> dim id <T1> as <T2> ; <T>
<T> ::= empty_string
<ET> ::= extern
<ET> ::= empty_string
<T1> ::= , id <T1>
<T1> ::= empty_string
...เรื่อยไปนะครับ
EBNF ใช้อธิบายโครงสร้างของภาษาหรือที่เรียกว่า "กฏไวยากรณ์" (syntax) ตัวผลิตจะอยู่ทางซ้ายของเครื่องหมาย ::= ส่วนผลิตผลจะอยู่ทางขวาของเครื่องหมาย ::=
EBNF ประกอบด้วย non-terminal และ terminal
นิยามอย่างง่ายที่สุด non-terminal สามารถแบ่งแยกได้เป็น non-terminal หรือ terminal อีกเท่าใดก็ได้
ส่วน terminal ไม่สามารถแบ่งแยกได้อีกแล้ว
ข้อตกลงทั่วไปสำหรับ non-terminal คือต้องเปิดด้วยเครื่องหมาย < และปิดด้วยเครื่องหมาย > เช่น <S> <B> <T> เป็นต้น ทว่าบางทีอาจารย์ท่านก็เขียนเพียงตัวอักษรเฉยๆ แต่อย่างไรก็คือ non-terminal เหมือนกัน ได้แก่ id ซึ่งย่อมาจาก identifier หมายถึงการตั้งชื่อตามกฎการตั้งชื่อตัวแปรของภาษาใดๆ (เรากำหนดเอาเองหรือเลียนแบบภาษา C ก็ได้)
และข้อตกลงทั่วไปสำหรับ terminal คือเป็นตัวอักษรเฉยๆ (ไม่นับ id นะครับ) จาก grammar ข้างต้น เช่น main เครื่องหมาย ( เครื่องหมาย ) เครื่องหมาย { เครื่องหมาย } เหล่านี้เป็นต้น
สุดท้ายสำหรับ empty_string นั้นหมายถึง ว่างเปล่า คือเลือกที่จะไม่ผลิตสิ่งใดหรือกล่าวว่าไม่มีผลิตผลใดๆ
ควรทราบว่า non-terminal อาจเขียนด้วยตัวพิมพ์ใหญ่ เช่น S B T เฉยๆ ไม่มีเครื่องหมาย < และ > ครอบก็เป็นได้ ขึ้นอยู่กับข้อตกลงและตำราที่ใช้เป็นหลัก ส่วน terminal ก็อาจเขียนเป็นตัวพิมพ์เล็กที่อาจมีเครื่องหมาย " และ " ครอบหรือไม่ก็ได้
เราควรอ่าน grammar ให้เป็น คือสามารถนำมันมาสร้างเป็น source code ได้ ตัวอย่าง
<S> ::= <Sp> main() { <B> }
<Sp> ::= id() { <B> } <Sp>
<Sp> ::= empty_string
ในเมื่อ <S> เป็น non-terminal เริ่มต้นของ grammar นี้ ตัวมันสามารถผลิต <Sp> main() { <B> } อย่างนี้จะสร้างเป็น source code อย่างง่ายที่สุดอย่างไร
- กำหนดให้ <Sp> ผลิตได้ empty_string
- กำหนดให้ <B> ผลิตได้ empty_string
ดังนั้น source code จึงเป็น
main() {
}
อ่านถึงตรงนี้พอเข้าใจไหมครับ ทีนี้หากว่า <Sp> ไม่ได้ผลิตเป็น empty_string แต่กลับได้เป็น id() { <B> } <Sp> และกำหนดให้ <B> ผลิตได้ empty_string ดังเดิม เมื่อนั้นหน้าตา source code ก็จะออกมาอย่างนี้
A() {
}
main() {
}
หรือ
A() {
}
myFunction() {
}
main() {
}
หรือทำนองใดๆ พอเข้าใจนะครับ คล้ายกับการประกาศฟังก์ชันแบบ inline ในภาษา C (ฟังก์ชันในภาษา C เรียกการเขียนฟังก์ชันใดๆไว้ก่อน main ว่า inline function มันจะจองหน่วยความจำเท่าที่ตัวฟังก์ชันระบุทันที โดยไม่สนใจว่าฟังก์ชันดังกล่าวจะถูกเรียกใช้หรือไม่ก็ตาม ต่างจากการเขียนฟักง์ชันหลัง main ซึ่งจะจองหน่วยความจำก็ต่อเมื่อเกิดการเรียกใช้ฟังก์ชันจากภายใน main เท่านั้น)
จาก source code ข้างต้นจะเห็นว่าตำแหน่ง id ของตัวผลิต <Sp> สามารถเปลี่ยนเป็นชื่อใดๆก็ได้ตามหลักการตั้งชื่อตัวแปรทั่วไป เช่น A myFunction B Phai น้องส้มโอน่ารัก หรือใดๆตราบเท่าที่เราต้องการ (ต้องอยู่ในข้อตกลงของอาจารย์ด้วยนะ)
สงสัยหรือต้องการให้เพิ่มเติมอย่างไรก็แสดงความเห็น (comment) ด้านล่างนี้ได้เลยครับ หากเข้าใจแล้วให้คลิกลิงค์สู่หน้าต่อไป
<< CT414 ภาค 1/54 | ตัดคำ >>
CT414 ภาค 1/54
สวัสดีครับเพื่อนๆ หนนี้ผมจะแนะนำการเขียนโปรแกรม Compiler ด้วยภาษา Java โดยอ้างอิงโจทย์ของน้อง "PetPraUMa" แห่ง "กระดานข่าว-ภาควิชาวิทยาการคอมพิวเตอร์" และประโยชน์ทั้งหมดขอยกให้กับเพื่อนใน Facebook ที่ชื่อ "Tong Slumberous" ครับ
ไหนๆก็รู้จักกันแล้ว ใครเขียนภาษา Java เป็นแล้วให้ข้ามส่วนนี้ไปได้เลย (อ่านหน้าต่อไปด้านล่างครับ) ถ้าใครเพิ่งเริ่มเขียนภาษา Java โปรดอ่านสักนิด เผื่อว่าเราจะได้เข้าใจในแนวทางเดียวกัน
Java ยากไหม ผมว่าไม่ยากเท่าความพยายามของเราหรอกครับ ถามก่อนว่าภาษา C เขียนเป็นไหม ถ้ายังไม่เป็นก็ควรเรียนรู้ไว้ เพราะ C เป็นภาษาโครงสร้างที่มีลำดับการทำงานจากบนลงล่าง ใช้เป็นภาษาพื้นฐานเพื่อเรียนรู้การเขียนโปรแกรมนั้นดี บ้างว่าเขียน Java ไปเลยไม่ดีกว่าหรือ ผมก็ว่าเป็นมุมมองที่ไม่แปลกอะไร เพราะอย่างไรภาษาที่เป็น OOP อย่าง Java หรือ C# ก็ยังต้องแบ่งคลาสออกเป็นเมธอด และเนื้อแท้ภายในเมธอดก็คือลำดับที่เป็นโครงสร้างดั่งภาษา C นั่นแหละครับ จะต่างกันที่แนวคิดและกลวิธีการเขียนเท่านั้นเอง
เอาล่ะ ควรรู้ Java ระดับไหนถึงจะเขียน Compiler ได้ ตามความเข้าใจของผมควรรู้เกี่ยวกับ เมธอด main, ชนิดข้อมูล, การประกาศตัวแปร, การใช้ตัวแปร, การแยกออกเป็นเมธอด (แบ่งเป็นฟังก์ชัน), การเรียกใช้เมธอด, การผ่าน arguments ให้เมธอด, การ override, การ overloading และ constructor เป็นอย่างน้อย เยอะไปใช่ไหม ก็นะ มันจำเป็นต้องเรียนรู้ ถือเสียว่าเดินทางไปเที่ยวในโลกของ Java หรือภาษาที่เป็น OOP ก็แล้วกันนะครับ แต่อย่างไรผมก็จะคุยเรื่องเหล่านี้ให้ฟังทั้งหมด เราต้องคิดไปด้วยกัน โอเคนะ งั้นมาเริ่มกันเลย
Class
คลาส ให้เข้าใจว่า คือการเขียนขึ้นเพื่อห่อหุ้ม หุ้มมันทำไม ก็เพื่อจัดหมวดหมู่ครับ ตัวอย่างเช่น มีกระเป๋าดินสอ กระเป๋าสตางค์ กระเป๋าใส่เสื้อผ้า กระเป๋าสำหรับใส่หนังสือไปเรียน กระเป๋าสำหรับเดินทาง เป็นต้น ถามว่าทั้งหมดนั่นกระเป๋าใช่ไหม ก็ว่าใช่ ล้วนเป็นกระเป๋าทั้งนั้น แต่มีหน้าที่แตกต่างกันไปเพื่อความเป็นระเบียบเรียบร้อยไงล่ะ ทีนี้มาดูสิ่งที่ควรอยู่ในกระเป๋าของภาษา Java กัน ที่ควรรู้จักตอนนี้คือ Attribute และ Method
Attribute
ภาษา C เขาเรียกกันว่า "ตัวแปร" (variable) แต่ละภาษามีวิธีประกาศตัวแปรแตกต่างกัน ขึ้นอยู่กับโครงสร้างทางไวยากรณ์ (syntax) ของภาษานั้นๆ ดูภาษา C กันก่อน
int a = 100;
แรกสุดเลยคือ int คือชนิดข้อมูลหรือ type เป็นชนิด integer สำหรับจำนวนเต็ม (เต็มลบ เต็มศูนย์และเต็มบวก)
ถัดมาคือ a หรือ identifier เราตั้งชื่อว่า a เฉยๆ
ถัดมาคือ = หรือ operator มีความหมายว่าให้ค่าทางซ้ายเท่ากับค่าทางขวา
ถัดมาคือ 100 หรือ constant ที่มีค่าหนึ่งร้อย
และสุดท้ายคือ ; หรือ separator เขียนเพื่อระบุว่าจบประโยคการประกาศตัวแปรแล้วนะ
เพียงเท่านี้เครื่องคอมฯของเราก็เข้าใจแล้วว่า ให้จัดการหน่วยความจำสำหรับเก็บค่า 100 และเรียกพื้นที่หน่วยความจำดังกล่าวว่า a ทีนี้หากต้องการค่า 100 มาใช้งานก็เพียงแต่เรียกชื่อ a
ต่อไปเมื่อต้องการนำค่า 100 แสดงผลทางจอภาพเราก็เขียนเป็นคำสั่ง
cout << a << endl;
หรือ
cout << 100 << endl;
ก็ได้ทั้งนั้น เด็กๆใช่ไหมล่ะ พอเข้าใจนะครับ ทีนี้มาดูภาษา Java กันบ้าง หากต้องการเลียนแบบก็เขียนได้ว่าอย่างนี้
int a = 100;
เหมือนกันอย่างแกะ เหลือแค่ศัพท์ที่เขาไม่เรียกกันว่าตัวแปร แต่จะเรียกว่า "แอตทริบิวต์" (attribute) นอกจากนี้เจ้าแอตทริบิวต์เนี่ยยังสามารถเพิ่มระดับความปลอดภัย (access modifier) ให้กับมันได้อีก ซึ่งเป็นคุณสมบัติประการหนึ่งที่ภาษา OOP พึงมี ได้แก่
public หมายถึง ใครๆก็เรียกใช้ได้ ระดับความปลอดภัยอ่อนสุด
ไม่ระบุ หมายถึง default คล้ายกับระดับความปลอดภัยภายใน folder, งานใดๆใน folder เดียวกันจึงเรียกใช้ได้
protected หมายถึง เฉพาะคลาสที่สืบทอดต่อๆกันมาจึงเรียกใช้ได้ ระดับความปลอดภัยปานกลาง
private หมายถึง ระดับความปลอดภัยสูงสุด คลาสเดียวกันเท่านั้นที่จะเรียกใช้ได้
เวลาประกาศตัวแปร ภาษา Java กำหนดให้สามารถระบุระดับความปลอดภัยแก่แอตทริบิวต์ จะใช้ระดับไหนขึ้นอยู่กับงานของเราและกลวิธีการออกแบบคลาสของเราเป็นหลักครับ ตัวอย่างเช่น
private int a = 100;
แบบนี้จำกัดให้ a ใช้ได้เฉพาะในคลาสของตัวเองเท่านั้น คลาสอื่นอย่าแหยม แต่ถ้า
public int a = 100;
แบบนี้คลาสใดๆก็สามารถเรียกใช้ a ได้ทั้งนั้น และในขั้นต้นนี้ผมแนะนำให้รู้จักเพียงสองระดับความปลอดภัย นั่นคือ private และ public
Method
ดูภาษา C ก่อน ต่อไปนี้เป็นการประกาษฟังก์ชันเพื่อนำตัวเลขจำนวนเต็มสองจำนวนมาบวกกัน แล้วส่งผลลัพธ์ที่ได้กลับไปยังที่เรียกใช้
int summation(int x, int y) {
return x + y;
}
และถ้าเป็นภาษา Java ล่ะ
int summation(int x, int y) {
return x + y;
}
เป๊ะ เหมือนกันทั้งหมด นอกจากนี้เรายังสามารถเพิ่มระดับความปลอดภัยให้กับเมธอด (method) เช่นเดียวกับแอตทริบิวต์ครับ
โจทย์ที่ 1 เขียนโปรแกรมบวกเลขสองจำนวนด้วยภาษา Java
- กำหนดให้คลาสชื่อว่า Calculate
- กำหนดให้เมธอดที่ทำงานบวกชื่อว่า summation
class Calculate {
public int summation(int x, int y) {
return x + y;
}
}
ทีนี้ก็เรียกใช้ที่คลาส Test1 ซึ่งมีเมธอด main
class Test1 {
public static void main(String[] args) {
Calculate cal = new Calculate();
System.out.println(cal.summation(10, 20));
}
}
ใครยังไม่เข้าใจหรือสงสัย หรือผมผิดพลาดประการใดสามารถแสดงความเห็น (comment) ได้ด้านล่างของหน้านี้เลยครับ
หากเข้าใจแล้วเรามาต่อกันเลย อ่านหน้าถัดไป
ไหนๆก็รู้จักกันแล้ว ใครเขียนภาษา Java เป็นแล้วให้ข้ามส่วนนี้ไปได้เลย (อ่านหน้าต่อไปด้านล่างครับ) ถ้าใครเพิ่งเริ่มเขียนภาษา Java โปรดอ่านสักนิด เผื่อว่าเราจะได้เข้าใจในแนวทางเดียวกัน
Java ยากไหม ผมว่าไม่ยากเท่าความพยายามของเราหรอกครับ ถามก่อนว่าภาษา C เขียนเป็นไหม ถ้ายังไม่เป็นก็ควรเรียนรู้ไว้ เพราะ C เป็นภาษาโครงสร้างที่มีลำดับการทำงานจากบนลงล่าง ใช้เป็นภาษาพื้นฐานเพื่อเรียนรู้การเขียนโปรแกรมนั้นดี บ้างว่าเขียน Java ไปเลยไม่ดีกว่าหรือ ผมก็ว่าเป็นมุมมองที่ไม่แปลกอะไร เพราะอย่างไรภาษาที่เป็น OOP อย่าง Java หรือ C# ก็ยังต้องแบ่งคลาสออกเป็นเมธอด และเนื้อแท้ภายในเมธอดก็คือลำดับที่เป็นโครงสร้างดั่งภาษา C นั่นแหละครับ จะต่างกันที่แนวคิดและกลวิธีการเขียนเท่านั้นเอง
เอาล่ะ ควรรู้ Java ระดับไหนถึงจะเขียน Compiler ได้ ตามความเข้าใจของผมควรรู้เกี่ยวกับ เมธอด main, ชนิดข้อมูล, การประกาศตัวแปร, การใช้ตัวแปร, การแยกออกเป็นเมธอด (แบ่งเป็นฟังก์ชัน), การเรียกใช้เมธอด, การผ่าน arguments ให้เมธอด, การ override, การ overloading และ constructor เป็นอย่างน้อย เยอะไปใช่ไหม ก็นะ มันจำเป็นต้องเรียนรู้ ถือเสียว่าเดินทางไปเที่ยวในโลกของ Java หรือภาษาที่เป็น OOP ก็แล้วกันนะครับ แต่อย่างไรผมก็จะคุยเรื่องเหล่านี้ให้ฟังทั้งหมด เราต้องคิดไปด้วยกัน โอเคนะ งั้นมาเริ่มกันเลย
Class
คลาส ให้เข้าใจว่า คือการเขียนขึ้นเพื่อห่อหุ้ม หุ้มมันทำไม ก็เพื่อจัดหมวดหมู่ครับ ตัวอย่างเช่น มีกระเป๋าดินสอ กระเป๋าสตางค์ กระเป๋าใส่เสื้อผ้า กระเป๋าสำหรับใส่หนังสือไปเรียน กระเป๋าสำหรับเดินทาง เป็นต้น ถามว่าทั้งหมดนั่นกระเป๋าใช่ไหม ก็ว่าใช่ ล้วนเป็นกระเป๋าทั้งนั้น แต่มีหน้าที่แตกต่างกันไปเพื่อความเป็นระเบียบเรียบร้อยไงล่ะ ทีนี้มาดูสิ่งที่ควรอยู่ในกระเป๋าของภาษา Java กัน ที่ควรรู้จักตอนนี้คือ Attribute และ Method
Attribute
ภาษา C เขาเรียกกันว่า "ตัวแปร" (variable) แต่ละภาษามีวิธีประกาศตัวแปรแตกต่างกัน ขึ้นอยู่กับโครงสร้างทางไวยากรณ์ (syntax) ของภาษานั้นๆ ดูภาษา C กันก่อน
int a = 100;
แรกสุดเลยคือ int คือชนิดข้อมูลหรือ type เป็นชนิด integer สำหรับจำนวนเต็ม (เต็มลบ เต็มศูนย์และเต็มบวก)
ถัดมาคือ a หรือ identifier เราตั้งชื่อว่า a เฉยๆ
ถัดมาคือ = หรือ operator มีความหมายว่าให้ค่าทางซ้ายเท่ากับค่าทางขวา
ถัดมาคือ 100 หรือ constant ที่มีค่าหนึ่งร้อย
และสุดท้ายคือ ; หรือ separator เขียนเพื่อระบุว่าจบประโยคการประกาศตัวแปรแล้วนะ
เพียงเท่านี้เครื่องคอมฯของเราก็เข้าใจแล้วว่า ให้จัดการหน่วยความจำสำหรับเก็บค่า 100 และเรียกพื้นที่หน่วยความจำดังกล่าวว่า a ทีนี้หากต้องการค่า 100 มาใช้งานก็เพียงแต่เรียกชื่อ a
ต่อไปเมื่อต้องการนำค่า 100 แสดงผลทางจอภาพเราก็เขียนเป็นคำสั่ง
cout << a << endl;
หรือ
cout << 100 << endl;
ก็ได้ทั้งนั้น เด็กๆใช่ไหมล่ะ พอเข้าใจนะครับ ทีนี้มาดูภาษา Java กันบ้าง หากต้องการเลียนแบบก็เขียนได้ว่าอย่างนี้
int a = 100;
เหมือนกันอย่างแกะ เหลือแค่ศัพท์ที่เขาไม่เรียกกันว่าตัวแปร แต่จะเรียกว่า "แอตทริบิวต์" (attribute) นอกจากนี้เจ้าแอตทริบิวต์เนี่ยยังสามารถเพิ่มระดับความปลอดภัย (access modifier) ให้กับมันได้อีก ซึ่งเป็นคุณสมบัติประการหนึ่งที่ภาษา OOP พึงมี ได้แก่
public หมายถึง ใครๆก็เรียกใช้ได้ ระดับความปลอดภัยอ่อนสุด
ไม่ระบุ หมายถึง default คล้ายกับระดับความปลอดภัยภายใน folder, งานใดๆใน folder เดียวกันจึงเรียกใช้ได้
protected หมายถึง เฉพาะคลาสที่สืบทอดต่อๆกันมาจึงเรียกใช้ได้ ระดับความปลอดภัยปานกลาง
private หมายถึง ระดับความปลอดภัยสูงสุด คลาสเดียวกันเท่านั้นที่จะเรียกใช้ได้
เวลาประกาศตัวแปร ภาษา Java กำหนดให้สามารถระบุระดับความปลอดภัยแก่แอตทริบิวต์ จะใช้ระดับไหนขึ้นอยู่กับงานของเราและกลวิธีการออกแบบคลาสของเราเป็นหลักครับ ตัวอย่างเช่น
private int a = 100;
แบบนี้จำกัดให้ a ใช้ได้เฉพาะในคลาสของตัวเองเท่านั้น คลาสอื่นอย่าแหยม แต่ถ้า
public int a = 100;
แบบนี้คลาสใดๆก็สามารถเรียกใช้ a ได้ทั้งนั้น และในขั้นต้นนี้ผมแนะนำให้รู้จักเพียงสองระดับความปลอดภัย นั่นคือ private และ public
Method
ดูภาษา C ก่อน ต่อไปนี้เป็นการประกาษฟังก์ชันเพื่อนำตัวเลขจำนวนเต็มสองจำนวนมาบวกกัน แล้วส่งผลลัพธ์ที่ได้กลับไปยังที่เรียกใช้
int summation(int x, int y) {
return x + y;
}
และถ้าเป็นภาษา Java ล่ะ
int summation(int x, int y) {
return x + y;
}
เป๊ะ เหมือนกันทั้งหมด นอกจากนี้เรายังสามารถเพิ่มระดับความปลอดภัยให้กับเมธอด (method) เช่นเดียวกับแอตทริบิวต์ครับ
โจทย์ที่ 1 เขียนโปรแกรมบวกเลขสองจำนวนด้วยภาษา Java
- กำหนดให้คลาสชื่อว่า Calculate
- กำหนดให้เมธอดที่ทำงานบวกชื่อว่า summation
class Calculate {
public int summation(int x, int y) {
return x + y;
}
}
ทีนี้ก็เรียกใช้ที่คลาส Test1 ซึ่งมีเมธอด main
class Test1 {
public static void main(String[] args) {
Calculate cal = new Calculate();
System.out.println(cal.summation(10, 20));
}
}
ใครยังไม่เข้าใจหรือสงสัย หรือผมผิดพลาดประการใดสามารถแสดงความเห็น (comment) ได้ด้านล่างของหน้านี้เลยครับ
หากเข้าใจแล้วเรามาต่อกันเลย อ่านหน้าถัดไป
วันพฤหัสบดีที่ 25 สิงหาคม พ.ศ. 2554
วันพุธที่ 24 สิงหาคม พ.ศ. 2554
กำหนดและติดตั้ง Simulator ของเจ้า Android SDK
เอาล่ะตอนนี้พี่ Eclipse รู้จักกับน้อง Android เรียบร้อยแล้ว ส่งสายตาประสานยิ้มหวาน ปิ้งๆ ต่อไปคือการกำหนดให้ตัว simulator ของ Android ทำงาน
- ยังอยู่ที่ Eclipse หาเมนูที่ชื่อ Window แล้วเลือก Preferences หน้าต่าง Preferences จะถูกเปิดขึ้นมา
- ซ้ายมือครับซ้ายมือ เพื่อนๆจะเห็นรายการของ Android (ก่อนหน้านี้ไม่มีนะ หากยังไม่ได้ติดตั้ง Android SDK) โอเช เห็นแล้วก็คลิกเลือกเลยครับ ผลคือด้านขวาจะปรากฏกลุ่ม Android Preferences แต่เอ๊ะ!
ตกกระจายหมด เขาขอบคุณที่ใช้ของของเขาเท่านั้นเอง (แบบว่าครั้งแรก อิอิ) ไม่มีอะไรน่ากังวล ตอบๆเขาไปตามมารยาท
- กลับมาที่กลุ่ม Android Preferences ในช่อง SDK Location ให้เพื่อนๆคลิกปุ่ม Browse... จากนั้นระบุไปยังไดเรกทอรี่ที่เราได้ขยาย android-sdk_r12-windows.zip เอาไว้ ซึ่งได้โฟลเดอร์ชื่อว่า android-sdk-windows แล้วตอบ OK เจ้าค่ะ

- ใกล้แล้วๆ ขั้นตอนต่อไป คือการกำหนด AVD (Android Virtual Devices) ให้มองหาเมนูชื่อ Window ตามเคย แล้วเลือก Android SDK and AVD Manager
- ด้านซ้ายมือจะมีอยู่สามเมนู ได้แก่ Virtual devices, Installed packages และ Available packages ให้เลือกเมนูที่สามก่อนเลย
- ด้านขวามือจะแสดงกลุ่ม Packages available for download ที่เครื่องของผม (เวอร์ชันขณะนี้) ปรากฏ
- Android Repository
- Third party Add-ons
- งานของเราเบื้องต้นนี้อยู่ที่ Android Repository ผมเลือกเพียง (เลือกเยอะโหลดนานเด้อ)
- Documentation for Android SDK, API13, revision1
- SDK Platform Android 3.2, API13, revision1
- Samples for SDK API13, revision1
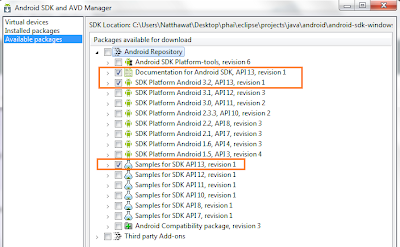
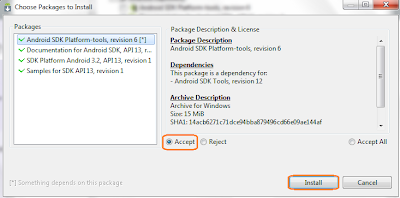
- จากนั้นกดปุ่ม Install Selected เขา (อีกแล้ว) จะให้เรายืนยันความต้องการที่ได้เลือกไว้ เอิ๊กๆ เลือก Accept แล้วกด Install เลยคร๊าบบบพี่น้อง (โปรดสังเกตภาพที่ผมนำมาประกอบ ผมเลือกเพียงสามรายการ แต่เขาแถมให้เป็นสี่รายการ อะจะบะฮื้ย! อีหยังนิ)
- รอ ร้อ รอ...ดาริ้ง (เครื่องผมใช้เวลาประมาณครึ่งชั่วโมงกว่า ไงเน็ตแรงดีมะ กึ๋ยๆ)
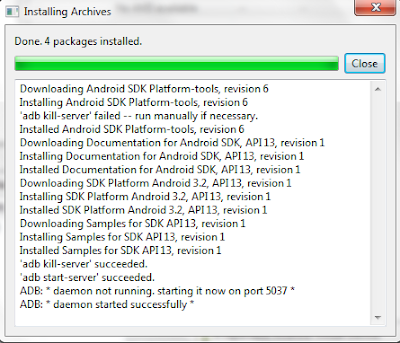
- เมื่อการดาวน์โหลดและติดตั้งแล้วเสร็จ (มันทำของมันเองหมดเลย) กดปุ่ม Close (ให้แน่ใจว่าเสร็จแล้วนะ เพราะปุ่ม Close นี่กดได้ตลอดเวลา -*- สุ่มสี่สุ่มหกกดไป ต้องทำใหม่หมด เดี๋ยวจะว่าไม่บอก อ๊าาากหัวแตก!) แล้วมาสร้าง Android Project กัน อิอิ ในที่สุดก็จะได้เห็นแล้ววว
อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า หรือ ถัดไป
- ยังอยู่ที่ Eclipse หาเมนูที่ชื่อ Window แล้วเลือก Preferences หน้าต่าง Preferences จะถูกเปิดขึ้นมา
- ซ้ายมือครับซ้ายมือ เพื่อนๆจะเห็นรายการของ Android (ก่อนหน้านี้ไม่มีนะ หากยังไม่ได้ติดตั้ง Android SDK) โอเช เห็นแล้วก็คลิกเลือกเลยครับ ผลคือด้านขวาจะปรากฏกลุ่ม Android Preferences แต่เอ๊ะ!

ตกกระจายหมด เขาขอบคุณที่ใช้ของของเขาเท่านั้นเอง (แบบว่าครั้งแรก อิอิ) ไม่มีอะไรน่ากังวล ตอบๆเขาไปตามมารยาท
- กลับมาที่กลุ่ม Android Preferences ในช่อง SDK Location ให้เพื่อนๆคลิกปุ่ม Browse... จากนั้นระบุไปยังไดเรกทอรี่ที่เราได้ขยาย android-sdk_r12-windows.zip เอาไว้ ซึ่งได้โฟลเดอร์ชื่อว่า android-sdk-windows แล้วตอบ OK เจ้าค่ะ

- ใกล้แล้วๆ ขั้นตอนต่อไป คือการกำหนด AVD (Android Virtual Devices) ให้มองหาเมนูชื่อ Window ตามเคย แล้วเลือก Android SDK and AVD Manager
- ด้านซ้ายมือจะมีอยู่สามเมนู ได้แก่ Virtual devices, Installed packages และ Available packages ให้เลือกเมนูที่สามก่อนเลย
- ด้านขวามือจะแสดงกลุ่ม Packages available for download ที่เครื่องของผม (เวอร์ชันขณะนี้) ปรากฏ
- Android Repository
- Third party Add-ons
- งานของเราเบื้องต้นนี้อยู่ที่ Android Repository ผมเลือกเพียง (เลือกเยอะโหลดนานเด้อ)
- Documentation for Android SDK, API13, revision1
- SDK Platform Android 3.2, API13, revision1
- Samples for SDK API13, revision1

- จากนั้นกดปุ่ม Install Selected เขา (อีกแล้ว) จะให้เรายืนยันความต้องการที่ได้เลือกไว้ เอิ๊กๆ เลือก Accept แล้วกด Install เลยคร๊าบบบพี่น้อง (โปรดสังเกตภาพที่ผมนำมาประกอบ ผมเลือกเพียงสามรายการ แต่เขาแถมให้เป็นสี่รายการ อะจะบะฮื้ย! อีหยังนิ)

- รอ ร้อ รอ...ดาริ้ง (เครื่องผมใช้เวลาประมาณครึ่งชั่วโมงกว่า ไงเน็ตแรงดีมะ กึ๋ยๆ)

- เมื่อการดาวน์โหลดและติดตั้งแล้วเสร็จ (มันทำของมันเองหมดเลย) กดปุ่ม Close (ให้แน่ใจว่าเสร็จแล้วนะ เพราะปุ่ม Close นี่กดได้ตลอดเวลา -*- สุ่มสี่สุ่มหกกดไป ต้องทำใหม่หมด เดี๋ยวจะว่าไม่บอก อ๊าาากหัวแตก!) แล้วมาสร้าง Android Project กัน อิอิ ในที่สุดก็จะได้เห็นแล้ววว
อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า หรือ ถัดไป
ดาวน์โหลดและติดตั้ง Android SDK ใน Eclipse
- เริ่มจาก ดาวน์โหลด
- Eclipse (.zip) มาเตรียมไว้ก่อน ผมเลือก
Eclipse IDE for Java EE Developers สำหรับ Windows 32 Bit
- Android SDK (.zip) มาเตรียมไว้ก่อน ผมเลือก
android-sdk_r12-windows.zip
- ขยาย .zip ได้โฟลเดอร์ซึ่งมีชื่อดังนี้
- eclipse
- android-sdk-windows
นำไปวางไว้ตำแหน่งใดก็ได้ในเครื่องครับ ขณะนี้แนะนำที่ C:\ ง่ายๆไม่คิดมาก เอิ๊กๆ และไม่ต้องติดตั้ง (ใช้งานได้เลย)
- เริ่มจากโฟลเดอร์ชื่อ eclipse เปิดเข้าไปครับ ว้าว! เมื่อพบไอคอนสีม่วงที่ชื่อ eclipse.exe คลิกเลยๆ
- เมื่อโปรแกรม Eclipse พร้อมใช้งานแล้ว (ขณะนี้เป็นครั้งแรก อิอิ) ให้หาเมนูที่ชื่อ Help แล้วเลือก Install New Software... ดังภาพด้านล่าง
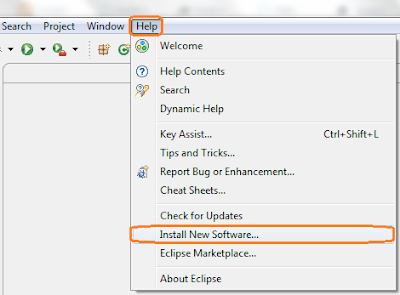
- หลังจากนั้นกดปุ่ม Add... เพื่อติดตั้งโปรแกรมใหม่ อิอิ ติดตั้งทางเน็ตซะด้วย นานแน่ๆ ดังภาพด้านล่างง๊าบ
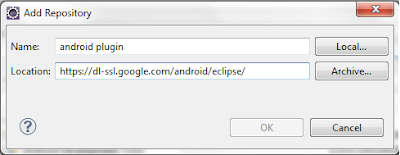
- สำหรับช่อง Name ให้ตั้งชื่ออะไรก็ได้ ผมใช้ android plugin
- และช่อง Location ให้ระบุเป็น https://dl-ssl.google.com/android/eclipse/ เท่านั้นจร้า เสร็จแล้วก็กด OK
- รอสักกำนึ่งเด้อ (รอสักครู่นะครับ) ด้านล่างของหน้าต่างเดียวกันนี้จะปรากฏสุดยอดไอเทมหายาก (= =!) ไม่ใช่ละครับ จะแสดงรายการให้เลือกว่าจะติดตั้งอะไรใหม่ (...นั่นสิ ติดตั้งอะไร?)
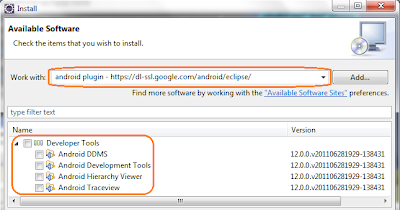
- ผมเลือกเพียง Android DDMS และ Android Development Tools สองอย่างนี้เท่านั้น (ใช้แค่นี้ก็เลือกแค่นี้สิ อิอิ ขืนเลือกหมดมีหวัง นาน นาน นาน) แล้วกดปุ่ม Next ขอรับ
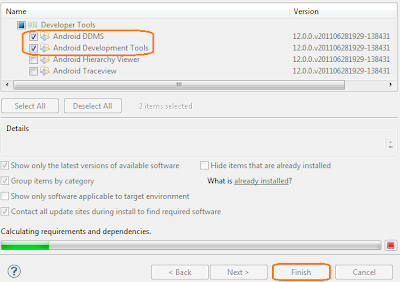
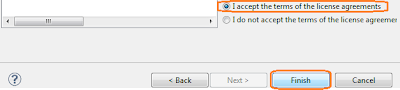
- แล้วเจ้า Eclipse ก็จะสรุปให้ฟังว่า โอเค ท่านได้เลือกอะไรบ้าง แน่ใจนะว่าจะติดตั้งจริงๆ (งั้นโปรดยืนยัน ยอมรับข้อตกลงด้วยเซ่ ประมาณนี้) เราไม่เคยอ่านกันหรอกครับ กดเลือก I accept ... ไปเลย (จะได้ผ่านๆไป อิอิ) แล้วกด Finish
- สุดท้ายของการสร้างตัวเรียก Android SDK ใน Eclipse แล้วละพี่น้อง รอแล้วก็รอ เน็ตช้า เต่า เน่า หลุด ก็กรรมไปเด้อ เอิ๊กๆ
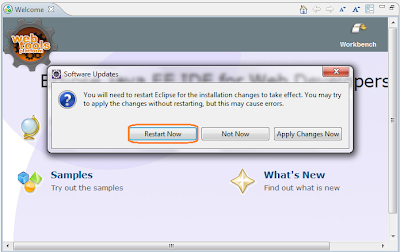
- อุ๊ย! มีอะไรใหม่ในตัวฉัน (Eclipse) ก็ไม่รู้ ถ้าอยากให้มันทำงานล่ะก็ Restart Now เลยนะตัวเอง จุ๊บๆ เป็นอันเรียบร้อยครับ
ตกลงเขียน Android ได้ยังจ๊ะ ตอบว่า ยังจ๊ะ! หัวข้อต่อไปคือการกำหนดและติดตั้ง Simulator ของเจ้า Android SDK (ที่เพิ่งทำเสร็จไปเนี่ยเพียงให้ Android SDK รู้จักกับเจ้า Eclipse เท่านั้นเอง กึ๋ยๆ) ตามมาๆ กดลิงค์ที่ชื่อ ถัดไป ด้านล่างของหน้านี้เลย อิอิ
อ่านเนื้อหาที่เกี่ยวข้อง ถัดไป
- Eclipse (.zip) มาเตรียมไว้ก่อน ผมเลือก
Eclipse IDE for Java EE Developers สำหรับ Windows 32 Bit
- Android SDK (.zip) มาเตรียมไว้ก่อน ผมเลือก
android-sdk_r12-windows.zip
- ขยาย .zip ได้โฟลเดอร์ซึ่งมีชื่อดังนี้
- eclipse
- android-sdk-windows
นำไปวางไว้ตำแหน่งใดก็ได้ในเครื่องครับ ขณะนี้แนะนำที่ C:\ ง่ายๆไม่คิดมาก เอิ๊กๆ และไม่ต้องติดตั้ง (ใช้งานได้เลย)
- เริ่มจากโฟลเดอร์ชื่อ eclipse เปิดเข้าไปครับ ว้าว! เมื่อพบไอคอนสีม่วงที่ชื่อ eclipse.exe คลิกเลยๆ
- เมื่อโปรแกรม Eclipse พร้อมใช้งานแล้ว (ขณะนี้เป็นครั้งแรก อิอิ) ให้หาเมนูที่ชื่อ Help แล้วเลือก Install New Software... ดังภาพด้านล่าง

- หลังจากนั้นกดปุ่ม Add... เพื่อติดตั้งโปรแกรมใหม่ อิอิ ติดตั้งทางเน็ตซะด้วย นานแน่ๆ ดังภาพด้านล่างง๊าบ
- สำหรับช่อง Name ให้ตั้งชื่ออะไรก็ได้ ผมใช้ android plugin
- และช่อง Location ให้ระบุเป็น https://dl-ssl.google.com/android/eclipse/ เท่านั้นจร้า เสร็จแล้วก็กด OK

- รอสักกำนึ่งเด้อ (รอสักครู่นะครับ) ด้านล่างของหน้าต่างเดียวกันนี้จะปรากฏสุดยอดไอเทมหายาก (= =!) ไม่ใช่ละครับ จะแสดงรายการให้เลือกว่าจะติดตั้งอะไรใหม่ (...นั่นสิ ติดตั้งอะไร?)

- ผมเลือกเพียง Android DDMS และ Android Development Tools สองอย่างนี้เท่านั้น (ใช้แค่นี้ก็เลือกแค่นี้สิ อิอิ ขืนเลือกหมดมีหวัง นาน นาน นาน) แล้วกดปุ่ม Next ขอรับ

- แล้วเจ้า Eclipse ก็จะสรุปให้ฟังว่า โอเค ท่านได้เลือกอะไรบ้าง แน่ใจนะว่าจะติดตั้งจริงๆ (งั้นโปรดยืนยัน ยอมรับข้อตกลงด้วยเซ่ ประมาณนี้) เราไม่เคยอ่านกันหรอกครับ กดเลือก I accept ... ไปเลย (จะได้ผ่านๆไป อิอิ) แล้วกด Finish

- สุดท้ายของการสร้างตัวเรียก Android SDK ใน Eclipse แล้วละพี่น้อง รอแล้วก็รอ เน็ตช้า เต่า เน่า หลุด ก็กรรมไปเด้อ เอิ๊กๆ
- อุ๊ย! มีอะไรใหม่ในตัวฉัน (Eclipse) ก็ไม่รู้ ถ้าอยากให้มันทำงานล่ะก็ Restart Now เลยนะตัวเอง จุ๊บๆ เป็นอันเรียบร้อยครับ

ตกลงเขียน Android ได้ยังจ๊ะ ตอบว่า ยังจ๊ะ! หัวข้อต่อไปคือการกำหนดและติดตั้ง Simulator ของเจ้า Android SDK (ที่เพิ่งทำเสร็จไปเนี่ยเพียงให้ Android SDK รู้จักกับเจ้า Eclipse เท่านั้นเอง กึ๋ยๆ) ตามมาๆ กดลิงค์ที่ชื่อ ถัดไป ด้านล่างของหน้านี้เลย อิอิ
อ่านเนื้อหาที่เกี่ยวข้อง ถัดไป
บทความที่เกี่ยวข้องกับเทคโนโลยี Android
เรียนรู้ Android จากเพื่อนสู่เพื่อน
- ดาวน์โหลดและติดตั้ง Android SDK ใน Eclipse
- กำหนดและติดตั้ง Simulator ของเจ้า Android SDK
- Android โปรแกรมแรก
Error แปลกๆที่มักพบในขณะพัฒนา Android
- "Error generating final archive: Debug certificate expired on dd/mm/yyyy"
เพื่อนบ้านที่น่ารัก ขอบคุณสำหรับข้อมูลดีๆ
- 7xment.blogspot.com
- www.itcyber.com
- www.unzeen.com
- developer.android.com
- ดาวน์โหลดและติดตั้ง Android SDK ใน Eclipse
- กำหนดและติดตั้ง Simulator ของเจ้า Android SDK
- Android โปรแกรมแรก
Error แปลกๆที่มักพบในขณะพัฒนา Android
- "Error generating final archive: Debug certificate expired on dd/mm/yyyy"
เพื่อนบ้านที่น่ารัก ขอบคุณสำหรับข้อมูลดีๆ
- 7xment.blogspot.com
- www.itcyber.com
- www.unzeen.com
- developer.android.com
วันจันทร์ที่ 6 มิถุนายน พ.ศ. 2554
ดาวน์โหลดโค้ด LL(1) และ SLR(1) จากในหนังสือเรียน
LL(1) ประกอบด้วยสามคลาส ได้แก่
- ParserTable สำหรับกำหนด production ในตาราง LL(1)
- Parser สำหรับกระบวนการ passing ตาราง LL(1)
- TestParser สำหรับรับ input เพื่อทดสอบการ passing (main program)
*** ควรเปิดด้วย NetBeans IDE เวอร์ชัน 6.9.1 ขึ้นไป
SLR(1) ประกอบด้วยสามคลาส ได้แก่
- ParserTable สำหรับกำหนด production ในตาราง SLR(1)
- Parser สำหรับกระบวนการ passing ตาราง SLR(1)
- TestParser สำหรับรับ input เพื่อทดสอบการ passing (main program)
*** ควรเปิดด้วย NetBeans IDE เวอร์ชัน 6.9.1 ขึ้นไป
วันจันทร์ที่ 18 เมษายน พ.ศ. 2554
สร้าง Web Application เบื้องต้น
เมื่อ Instant Rails พร้อมใช้งาาน ให้เราทดลองสร้างเว็บแอปพลิเคชัน (web application) แบบง่ายๆกันก่อนดังนี้
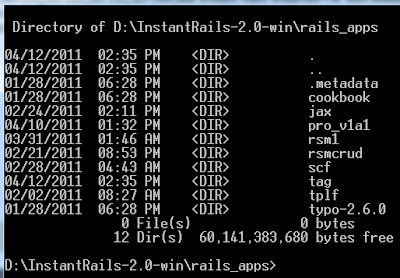
>> เรียก command prompt ขึ้นมา แล้วพิมพ์ use_ruby แล้วกด enter
- จะปรากฏผลลัพธ์ดังบรรทัดด้านล่างของรูป
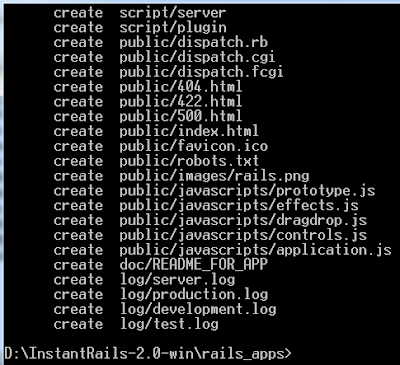
>> เรียกใช้คำสั่ง rails เว้นวรรคแล้วตามด้วยชื่อเว็บแอปพลิเคชันที่ต้องการ แล้วกด enter
- ตัวอย่างนี้ใช้ชื่อ test_app ดังนี้ rails test_app
- รูปด้านล่างแสดงให้เห็นว่าเกิดการสร้างโฟลเดอร์และไฟล์จำนวนหนึ่งให้อัตโนมัติ
>> เข้าสู่ไดเรกทอรีข้างต้นด้วยคำสั่ง cd เว้นวรรคตามด้วยชื่อไดเรกทอรี แล้วกด enter
- ตัวอย่างนี้คือ cd test_app

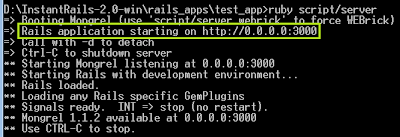
>> เรียกให้เว็บเซิร์ฟเวอร์ (web server) ทำงานเว็บแอปพลิเคชันของเรา โดยพิมพ์
>> เปิดบราวเซอร์เพื่อเรียกหน้า index.html ของเว็บแอปพลิเคชันดังกล่าว โดยพิมพ์ http://localhost:3000 ลงไปในช่อง URL
- เมื่อได้ดังภาพนีัจึงถือว่าสำเร็จแล้ว

อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า หรือ ถัดไป
>> เรียก command prompt ขึ้นมา แล้วพิมพ์ use_ruby แล้วกด enter
- จะปรากฏผลลัพธ์ดังบรรทัดด้านล่างของรูป

>> เรียกใช้คำสั่ง rails เว้นวรรคแล้วตามด้วยชื่อเว็บแอปพลิเคชันที่ต้องการ แล้วกด enter
- ตัวอย่างนี้ใช้ชื่อ test_app ดังนี้ rails test_app
- รูปด้านล่างแสดงให้เห็นว่าเกิดการสร้างโฟลเดอร์และไฟล์จำนวนหนึ่งให้อัตโนมัติ

>> เข้าสู่ไดเรกทอรีข้างต้นด้วยคำสั่ง cd เว้นวรรคตามด้วยชื่อไดเรกทอรี แล้วกด enter
- ตัวอย่างนี้คือ cd test_app

>> เรียกให้เว็บเซิร์ฟเวอร์ (web server) ทำงานเว็บแอปพลิเคชันของเรา โดยพิมพ์
ruby script/server
- ภาพด้านล่างนี้บอกรายละเอียดการทำงานของเว็บเซิร์ฟเวอร์และหมายเลขพอร์ต
>> เปิดบราวเซอร์เพื่อเรียกหน้า index.html ของเว็บแอปพลิเคชันดังกล่าว โดยพิมพ์ http://localhost:3000 ลงไปในช่อง URL
- เมื่อได้ดังภาพนีัจึงถือว่าสำเร็จแล้ว

อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า หรือ ถัดไป
สร้าง Web Application เบื้องต้น
เมื่อ Instant Rails พร้อมใช้งาาน ให้เราทดลองสร้างเว็บแอปพลิเคชัน (web application) แบบง่ายๆกันก่อนดังนี้
>> เรียก command prompt ขึ้นมา แล้วพิมพ์ use_ruby แล้วกด enter
- จะปรากฏผลลัพธ์ดังบรรทัดด้านล่างของรูป
>> เรียกใช้คำสั่ง rails เว้นวรรคแล้วตามด้วยชื่อเว็บแอปพลิเคชันที่ต้องการ แล้วกด enter
- ตัวอย่างนี้ใช้ชื่อ test_app ดังนี้ rails test_app
- รูปด้านล่างแสดงให้เห็นว่าเกิดการสร้างโฟลเดอร์และไฟล์จำนวนหนึ่งให้อัตโนมัติ
>> เข้าสู่ไดเรกทอรีข้างต้นด้วยคำสั่ง cd เว้นวรรคตามด้วยชื่อไดเรกทอรี แล้วกด enter
- ตัวอย่างนี้คือ cd test_app
>> เรียกให้เว็บเซิร์ฟเวอร์ (web server) ทำงานเว็บแอปพลิเคชันของเรา โดยพิมพ์ ruby script/server
- ภาพด้านล่างนี้บอกรายละเอียดการทำงานของเว็บเซิร์ฟเวอร์และหมายเลขพอร์ต
>> เปิดบราวเซอร์เพื่อเรียกหน้า index.html ของเว็บแอปพลิเคชันดังกล่าว โดยพิมพ์ http://localhost:3000/ ลงไปในช่อง URL
>> เรียก command prompt ขึ้นมา แล้วพิมพ์ use_ruby แล้วกด enter
- จะปรากฏผลลัพธ์ดังบรรทัดด้านล่างของรูป
>> เรียกใช้คำสั่ง rails เว้นวรรคแล้วตามด้วยชื่อเว็บแอปพลิเคชันที่ต้องการ แล้วกด enter
- ตัวอย่างนี้ใช้ชื่อ test_app ดังนี้ rails test_app
- รูปด้านล่างแสดงให้เห็นว่าเกิดการสร้างโฟลเดอร์และไฟล์จำนวนหนึ่งให้อัตโนมัติ
>> เข้าสู่ไดเรกทอรีข้างต้นด้วยคำสั่ง cd เว้นวรรคตามด้วยชื่อไดเรกทอรี แล้วกด enter
- ตัวอย่างนี้คือ cd test_app
>> เรียกให้เว็บเซิร์ฟเวอร์ (web server) ทำงานเว็บแอปพลิเคชันของเรา โดยพิมพ์ ruby script/server
- ภาพด้านล่างนี้บอกรายละเอียดการทำงานของเว็บเซิร์ฟเวอร์และหมายเลขพอร์ต
>> เปิดบราวเซอร์เพื่อเรียกหน้า index.html ของเว็บแอปพลิเคชันดังกล่าว โดยพิมพ์ http://localhost:3000/ ลงไปในช่อง URL
วันอังคารที่ 29 มีนาคม พ.ศ. 2554
ออกแบบ Grammar วิชา Compiler
ก่อนเข้าสู่ตัวอย่างวิธีการออกแบบ รบกวนเพื่อนๆอ่านบทความหน้านี้ก่อนครับ Compiler : ออกแบบ Grammar และขออนุญาตใช้ความคิดเห็นของเพื่อนชื่อ boyle หรือเพื่อน บอย เป็นโครงหลักของเนื้อหานะครับ อ่านความคิดเห็นของ boyle (อยู่ด้านล่างของหน้า)
ต่อไปนี้เป็นข้อตกลงใหม่ระหว่างผมกับเพื่อนๆนะครับ เนื่องจากการเขียนเครื่องหมาย < และ > ค่อนข้างลำบากสำหรับผมนิดหน่อย (เพราะต้องเขียนหน้า html และพอ update หน้าเพจแล้วมันเช้าใจว่าผมเขียนแท็ก html จึงแสดงผลผิดเพี้ยน) เอาเป็นว่า
- สำหรับ non-terminal ผมจะเขียนด้วยพิมพ์ใหญ่ เช่น START, VARIABLE เป็นต้น
- สำหรับ terminal ผมจะเขียนด้วยพิมพ์เล็กมีเครื่องหมาย " และ " ครอบด้วย เช่น "start", "variable" เป็นต้น
- ใช้เครื่องหมาย ::= แทนการผลิตจาก non-terminal เป็น terminal นะครับ (เพื่อนๆจะใช้เครื่องหมายลูกศร -> ก็ได้)
เพื่อนๆหลายคนสงสัยว่าเมื่อเริ่มออกแบบ grammar นั้นควร ออกแบบอย่างไร ควรเริ่มจากเปลี่ยน source code ตัวอย่างเป็น grammar ดีไหม หรือจาก grammar เป็น source code ดีกว่า...อื่ม อันนี้แล้วแต่ความเข้าใจและความถนัดของแต่ละคนครับ (ยิ้ม)
ส่วนตัวผมแล้วต้องใช้ทั้งสองแบบ กล่าวคือใช้แบบ source code เปลี่ยนเป็น grammar ก่อนห้าสิบเปอร์เซ็นต์ แล้วที่เหลือก็ใช้แบบ grammar เปลี่ยนเป็น source code ครับ เพราะอย่างไรก็ต้องจินตนาการถึง source code อื่นๆที่สามารถเกิดขึ้นได้อยู่ดี หรือกล่าวว่าเราไม่สามารถเขียน source code ทั้งหมดออกมาได้ แต่สามารถกำหนดรูปแบบของมันได้โดยใช้ grammar นั่นเอง เอาละครับมาเริ่มกันเลยนะ (ยิ้มให้อีกแล้วนะ)
ตัวอย่างที่ 1
var a
ง่ายๆก่อนนะครับ source code นี้เริ่มต้นด้วยคำว่า var แล้วตามด้วยตัวแปรชื่อ a แน่นอนว่าต่อไป a อาจเปลี่ยนเป็น b หรือ c หรือ love_you อะไรก็ได้จริงไหมครับ (ก็มันเป็นชื่อตัวแปร) ส่วนคำว่า var นั่นไม่เปลี่ยนแปลงเพราะมันเป็นคำสงวน ดังนั้นหากเป็นผมจะออกแบบ grammar ดังนี้ครับ
START ::= "var" VARIABLE
VARIABLE ::= LETTER { LETTER | DIGIT | "_" }
LETTER ::= a | b | c | ... | x | y | z | A | B | C | ... | X | Y | Z
DIGIT ::= 0 | 1 | 2 | ... | 7 | 8 | 9
***หมายเหตุ
- เครื่องหมาย { และ } หมายถึงผลิตเป็นจำนวนเท่าใดก็ได้ หยุดได้ตามต้องการ หรือเรียกว่า zero or more
- เครื่องหมาย | หมายถึง หรือ
ตัวอย่างที่ 2
var a, b, c : int
source code ข้างต้นนี้เพิ่มการประกาศแบบหลายตัวในครั้งเดียว และยังกำหนดชนิดข้อมูล (type) ได้อีกต่างหาก เช่น int หรือ float หรือ double หรือ หรือ char หรือ string หรือ bool เป็นต้น (จินตนานการเอานะครับ ว่ามันอาจเป็นอะไรได้อีก ก็กำหนดลงใน grammar เลย) จาก grammar ในตัวอย่างที่ 1 เราเพิ่ม grammar ส่วนที่เหลือดังนี้ครับ
START ::= "var" VARIABLE { "," VARIABLE } ":" TYPE
TYPE ::= "int" | "float" | "double" | "char" | "string" | "bool"
ตัวอย่างที่ 3
b:real
c: bool
d : string
ตัวอย่างนี้เราสามารถประกาศตัวแปรหรือกำหนดชนิดข้อมูลให้กับตัวแปรได้ภายหลังครับ ดังนั้นผมจึงเปลี่ยนแปลง grammar ในตัวอย่างที่ 2 เสียก่อน (เขียนแต่หลักๆนะครับ) แล้วเพิ่ม grammar ของตัวอย่างที่ 3 เข้าไปดังนี้
START ::= DECLARE1 | { DECLARE2 }
DECLARE1 ::= "var" VARIABLE { "," VARIABLE } ":" TYPE
DECLARE2 ::= VARIABLE ":" TYPE
grammar ข้างต้นนี้เราสามารถกระทำตาม source code ของตัวอย่างที่ 3 ได้ไม่จำกัดจำนวนครั้ง ทว่าสำหรับตัวอย่างที่ 2 นั้นสามารถกระทำได้เพียงครั้งเดียว ดังนั้นหากต้องการให้สามารถประกาศตัวแปรในตัวอย่างที่ 2 ได้ไม่จำกัดจำนวนครั้งเช่นกัน จึงปรับปรุงโดยเพิ่มเครื่องหมาย { } ครับ
START ::= { DECLARE1 } | { DECLARE2 }
ตัวอย่างที่ 4
While() do; ตามด้วย source code อื่นๆแล้วจบด้วย end;
เข้าสู่ while ลูปแล้วนะครับ หมายความว่าหากเป็นโปรแกรมจริงๆมันจะกระทำตามรอบที่ถูกกำหนดเป็น expression หรือเงื่อนไข (condition) ดังนั้นเราอาจออกแบบ grammar ได้ดังนี้
START ::= VARIABLE_DECLARATION | BODY
VARIABLE_DECLARATION ::= { DECLARE1 } | { DECLARE2 }
BODY ::= { WHILE }
WHILE ::= "while" "(" EXPR ")" "do" ";" STATEMENT "end" ";"
***หมายเหตุ
- EXPR หมายถึง expression หมายถึงเงื่อนไขตรรกศาสตร์หรือการคำนวณค่าต่างๆ ที่ให้ผลเป็น true หรือ false หรือค่า (value) ซึ่งจะแสดงในภายหลัง
- STATEMENT ในที่นี้หมายถึงการกำหนดค่าให้ตัวแปร การใช้ while หรือ if หรือการเรียกฟังก์ชัน เป็นต้น ซึ่งจะแสดงภายหลัง
- grammar ไม่มีผลบังคับให้เกิดรอบนะครับ เราออกแบบ grammar เพื่อกำหนด syntax ของภาษาเท่านั้น ส่วนรอบเราใช้ semantic ช่วยสร้างโค้ดภาษาเครื่องก่อน แล้วโค้ดภาษาเครื่องจึงทำให้เกิดรอบจริงๆอีกทีหนึ่ง หากมันสามารถรันได้จริงอะนะ
ตัวอย่างที่ 5
if() then ตามด้วย source code อื่นๆแล้วจบด้วย end;
ก็คล้ายกับตัวอย่างที่ 4 ครับเพียงแต่เพิ่ม if เข้ามา สามารถออกแบบเพิ่มได้ดังนี้ครับ
BODY ::= WHILE | { IF }
IF ::= "if" "(" EXPR ")" "then" STATEMENT "end" ";"
และหากว่า if นี้มี else ด้วยแล้ว ซึ่งอาจมีหน้าตา source code ดังนี้
if ( a > b ) then
a = a + 1;
else
b = b * 10;
end;
เช่นนั้นสามารถปรับเปลี่ยน grammar ได้ดั่งใจฝัน (เวอร์จริงๆ)
IF ::= "if" "(" EXPR ")" "then" STATEMENT [ "else" STATEMENT ] "end" ";"
STATEMENT ::= { ASSIGNMENT | WHILE | IF }
ASSIGNMENT ::= VARIABLE "=" EXPR ";"
***หมายเหตุ
- เครื่องหมาย [ และ ] หมายถึง มี หรือ ไม่มี ก็ได้ หากมีสามารถมีได้เพียงหนึ่ง หรือเรียกว่า zero or one
เป็นอย่างไรบ้างครับ จากตัวอย่างข้างต้นพอเข้าใจไหม ค่อยๆลองเขียนนะครับ ผิดถูกอย่างไรให้ลองไล่ด้วย source code ที่ต้องการให้เป็นไปทีละประโยค ขาดก็แก้ไข เกินก็ตัดออก ต่อไปนี้คือ grammar ทั้งหมดตั้งแต่เริ่มต้น (ไม่มีรายละเอียดของ EXPR นะครับ)
START ::= VARIABLE_DECLARATION | BODY
VARIABLE_DECLARATION ::= { DECLARE1 } | { DECLARE2 }
DECLARE1 ::= "var" VARIABLE { "," VARIABLE } ":" TYPE
DECLARE2 ::= VARIABLE ":" TYPE
VARIABLE ::= LETTER { LETTER | DIGIT | "_" }
LETTER ::= a | b | c | ... | x | y | z | A | B | C | ... | X | Y | Z
DIGIT ::= 0 | 1 | 2 | ... | 7 | 8 | 9
TYPE ::= "int" | "float" | "double" | "char" | "string" | "bool"
BODY ::= { WHILE } | { IF }
WHILE ::= "while" "(" EXPR ")" "do" ";" STATEMENT "end" ";"
IF ::= "if" "(" EXPR ")" "then" STATEMENT [ "else" STATEMENT ] "end" ";"
STATEMENT ::= { ASSIGNMENT | WHILE | IF }
ASSIGNMENT ::= VARIABLE "=" EXPR ";"
เราสามารถปรับเปลี่ยน grammar ให้ดียิ่งขึ้น โดยเปลี่ยนการผลิตของ non-terminal ชื่อ BODY และ STATEMENT เสียใหม่ แน่นอนว่าผลของมันทำให้ grammar สามารถกำหนดค่าให้ตัวแปร (ASSIGNMENT) ได้ก่อนการใช้ while หรือ if อีกด้วย ดังนี้
BODY ::= { STATEMENT }
STATEMENT ::= ASSIGNMENT | WHILE | IF
หากเราต้องการให้ grammar สามารถประกาศตัวแปร (VARIABLE_DECLARATION) ภายใน while หรือ if ได้ ก็เพียงแต่ปรับ grammar เป็นดังนี้
STATEMENT ::=
ASSIGNMENT | WHILE | IF | VARIABLE_DECLARATION
ตัวอย่างที่ 6
Program CT414; //ประกาศฟัง์ชันชื่อ CT414
var a:int
b:real
c:bool
Begin
While( a > b + 2 ) do;
a = a - 1;
end;
sub(); //เรียกซับฟังก์ชันชื่อ sub ในในฟังก์ชันอีกที
end;
Begin //เริ่มต้นฟังก์ชัน main
CT414(); //เรียกซับฟังก์ชันชื่อ CT414
end. //สิ้นสุดฟังก์ชัน main
ตัวอย่าง source code ข้างต้นนี้ก็ไม่ยากนัก หากเพื่อนๆสามารถเข้าใจตัวอย่างก่อนหน้านี้ได้ทั้งหมด (ค่อยเป็นค่อยไปนะครับ ผมให้กำลังใจ และเข้าใจผู้ที่เริ่มต้นออกแบบทุกคน เพราะผมก็ไม่มีใครสอนเป็นพิเศษ ใช้ทั้งความจำและการสังเกตเรียนรู้ด้วยตัวเองเรื่อยมา ผิดถูกอย่างไรขออภัยด้วยครับ) เราอาจแบ่ง grammar ออกเป็นสองส่วนเสียก่อน ดังนี้ (rewrite grammar เดิม เขียนเฉพาะหลักๆนะครับ)
START ::= { FUNCTION_DECLARATION } MAIN
กำหนดให้ FUNCTION_DECLARATION คือส่วนการประกาศฟังก์ชัน เช่น Program CT414 และให้ MAIN คือส่วน main function
FUNCTION_DECLARATION ::=
"Program" VARIABLE ";" FUNCTION_BODY
FUNCTION_BODY ::= VARIABLE_DECLARATION "Begin" BODY "end" ";"
MAIN ::= "Begin" BODY "end" "."
สุดท้ายปรับ STATEMENT ให้สามารถเรียกซับฟังก์ชัน (sub function หรือฟังก์ชันย่อย) ดังต่อไปนี้จึงเป็นอันว่าแล้วเสร็จครับ
STATEMENT ::=
ASSIGNMENT | WHILE | IF | VARIABLE_DECLARATION
| CALL_FUNCTION
CALL_FUNCTION ::= VARIABLE "(" [ ARGUMENT ] ")" ";"
***หมายเหตุ
- ARGUMENT นี้หมายถึง ตัวแปรหรือค่าคงที่ (const) หรือ EXPR ที่ต้องการส่งให้กับฟังก์ชัน เพราะบางฟังก์ชันสามารถรับค่าได้ แต่บางฟังก์ชันก็ไม่สามารถรับค่าได้ ดังนั้นควรออกแบบให้ มี หรือ ไม่มี ก็ได้ จึงเลือกใช้เครื่องหมาย [ ] ครับ
หวังว่าเนื้อหาเหล่านี้คงช่วยให้เพื่อนๆสามารถออกแบบ grammar ได้เองในระดับหนึ่ง ถือว่าเป็นการเล่าสู่กันฟังแล้วกันนะครับ โอกาศหน้าค่อยเจอกันใหม่ พยายามเข้านะครับ ^^
อ่านเนื้อหาที่เกี่ยวข้อง ถัดไป
ต่อไปนี้เป็นข้อตกลงใหม่ระหว่างผมกับเพื่อนๆนะครับ เนื่องจากการเขียนเครื่องหมาย < และ > ค่อนข้างลำบากสำหรับผมนิดหน่อย (เพราะต้องเขียนหน้า html และพอ update หน้าเพจแล้วมันเช้าใจว่าผมเขียนแท็ก html จึงแสดงผลผิดเพี้ยน) เอาเป็นว่า
- สำหรับ non-terminal ผมจะเขียนด้วยพิมพ์ใหญ่ เช่น START, VARIABLE เป็นต้น
- สำหรับ terminal ผมจะเขียนด้วยพิมพ์เล็กมีเครื่องหมาย " และ " ครอบด้วย เช่น "start", "variable" เป็นต้น
- ใช้เครื่องหมาย ::= แทนการผลิตจาก non-terminal เป็น terminal นะครับ (เพื่อนๆจะใช้เครื่องหมายลูกศร -> ก็ได้)
เพื่อนๆหลายคนสงสัยว่าเมื่อเริ่มออกแบบ grammar นั้นควร ออกแบบอย่างไร ควรเริ่มจากเปลี่ยน source code ตัวอย่างเป็น grammar ดีไหม หรือจาก grammar เป็น source code ดีกว่า...อื่ม อันนี้แล้วแต่ความเข้าใจและความถนัดของแต่ละคนครับ (ยิ้ม)
ส่วนตัวผมแล้วต้องใช้ทั้งสองแบบ กล่าวคือใช้แบบ source code เปลี่ยนเป็น grammar ก่อนห้าสิบเปอร์เซ็นต์ แล้วที่เหลือก็ใช้แบบ grammar เปลี่ยนเป็น source code ครับ เพราะอย่างไรก็ต้องจินตนาการถึง source code อื่นๆที่สามารถเกิดขึ้นได้อยู่ดี หรือกล่าวว่าเราไม่สามารถเขียน source code ทั้งหมดออกมาได้ แต่สามารถกำหนดรูปแบบของมันได้โดยใช้ grammar นั่นเอง เอาละครับมาเริ่มกันเลยนะ (ยิ้มให้อีกแล้วนะ)
ตัวอย่างที่ 1
var a
ง่ายๆก่อนนะครับ source code นี้เริ่มต้นด้วยคำว่า var แล้วตามด้วยตัวแปรชื่อ a แน่นอนว่าต่อไป a อาจเปลี่ยนเป็น b หรือ c หรือ love_you อะไรก็ได้จริงไหมครับ (ก็มันเป็นชื่อตัวแปร) ส่วนคำว่า var นั่นไม่เปลี่ยนแปลงเพราะมันเป็นคำสงวน ดังนั้นหากเป็นผมจะออกแบบ grammar ดังนี้ครับ
START ::= "var" VARIABLE
VARIABLE ::= LETTER { LETTER | DIGIT | "_" }
LETTER ::= a | b | c | ... | x | y | z | A | B | C | ... | X | Y | Z
DIGIT ::= 0 | 1 | 2 | ... | 7 | 8 | 9
***หมายเหตุ
- เครื่องหมาย { และ } หมายถึงผลิตเป็นจำนวนเท่าใดก็ได้ หยุดได้ตามต้องการ หรือเรียกว่า zero or more
- เครื่องหมาย | หมายถึง หรือ
ตัวอย่างที่ 2
var a, b, c : int
source code ข้างต้นนี้เพิ่มการประกาศแบบหลายตัวในครั้งเดียว และยังกำหนดชนิดข้อมูล (type) ได้อีกต่างหาก เช่น int หรือ float หรือ double หรือ หรือ char หรือ string หรือ bool เป็นต้น (จินตนานการเอานะครับ ว่ามันอาจเป็นอะไรได้อีก ก็กำหนดลงใน grammar เลย) จาก grammar ในตัวอย่างที่ 1 เราเพิ่ม grammar ส่วนที่เหลือดังนี้ครับ
START ::= "var" VARIABLE { "," VARIABLE } ":" TYPE
TYPE ::= "int" | "float" | "double" | "char" | "string" | "bool"
ตัวอย่างที่ 3
b:real
c: bool
d : string
ตัวอย่างนี้เราสามารถประกาศตัวแปรหรือกำหนดชนิดข้อมูลให้กับตัวแปรได้ภายหลังครับ ดังนั้นผมจึงเปลี่ยนแปลง grammar ในตัวอย่างที่ 2 เสียก่อน (เขียนแต่หลักๆนะครับ) แล้วเพิ่ม grammar ของตัวอย่างที่ 3 เข้าไปดังนี้
START ::= DECLARE1 | { DECLARE2 }
DECLARE1 ::= "var" VARIABLE { "," VARIABLE } ":" TYPE
DECLARE2 ::= VARIABLE ":" TYPE
grammar ข้างต้นนี้เราสามารถกระทำตาม source code ของตัวอย่างที่ 3 ได้ไม่จำกัดจำนวนครั้ง ทว่าสำหรับตัวอย่างที่ 2 นั้นสามารถกระทำได้เพียงครั้งเดียว ดังนั้นหากต้องการให้สามารถประกาศตัวแปรในตัวอย่างที่ 2 ได้ไม่จำกัดจำนวนครั้งเช่นกัน จึงปรับปรุงโดยเพิ่มเครื่องหมาย { } ครับ
START ::= { DECLARE1 } | { DECLARE2 }
ตัวอย่างที่ 4
While() do; ตามด้วย source code อื่นๆแล้วจบด้วย end;
เข้าสู่ while ลูปแล้วนะครับ หมายความว่าหากเป็นโปรแกรมจริงๆมันจะกระทำตามรอบที่ถูกกำหนดเป็น expression หรือเงื่อนไข (condition) ดังนั้นเราอาจออกแบบ grammar ได้ดังนี้
START ::= VARIABLE_DECLARATION | BODY
VARIABLE_DECLARATION ::= { DECLARE1 } | { DECLARE2 }
BODY ::= { WHILE }
WHILE ::= "while" "(" EXPR ")" "do" ";" STATEMENT "end" ";"
***หมายเหตุ
- EXPR หมายถึง expression หมายถึงเงื่อนไขตรรกศาสตร์หรือการคำนวณค่าต่างๆ ที่ให้ผลเป็น true หรือ false หรือค่า (value) ซึ่งจะแสดงในภายหลัง
- STATEMENT ในที่นี้หมายถึงการกำหนดค่าให้ตัวแปร การใช้ while หรือ if หรือการเรียกฟังก์ชัน เป็นต้น ซึ่งจะแสดงภายหลัง
- grammar ไม่มีผลบังคับให้เกิดรอบนะครับ เราออกแบบ grammar เพื่อกำหนด syntax ของภาษาเท่านั้น ส่วนรอบเราใช้ semantic ช่วยสร้างโค้ดภาษาเครื่องก่อน แล้วโค้ดภาษาเครื่องจึงทำให้เกิดรอบจริงๆอีกทีหนึ่ง หากมันสามารถรันได้จริงอะนะ
ตัวอย่างที่ 5
if() then ตามด้วย source code อื่นๆแล้วจบด้วย end;
ก็คล้ายกับตัวอย่างที่ 4 ครับเพียงแต่เพิ่ม if เข้ามา สามารถออกแบบเพิ่มได้ดังนี้ครับ
BODY ::= WHILE | { IF }
IF ::= "if" "(" EXPR ")" "then" STATEMENT "end" ";"
และหากว่า if นี้มี else ด้วยแล้ว ซึ่งอาจมีหน้าตา source code ดังนี้
if ( a > b ) then
a = a + 1;
else
b = b * 10;
end;
เช่นนั้นสามารถปรับเปลี่ยน grammar ได้ดั่งใจฝัน (เวอร์จริงๆ)
IF ::= "if" "(" EXPR ")" "then" STATEMENT [ "else" STATEMENT ] "end" ";"
STATEMENT ::= { ASSIGNMENT | WHILE | IF }
ASSIGNMENT ::= VARIABLE "=" EXPR ";"
***หมายเหตุ
- เครื่องหมาย [ และ ] หมายถึง มี หรือ ไม่มี ก็ได้ หากมีสามารถมีได้เพียงหนึ่ง หรือเรียกว่า zero or one
เป็นอย่างไรบ้างครับ จากตัวอย่างข้างต้นพอเข้าใจไหม ค่อยๆลองเขียนนะครับ ผิดถูกอย่างไรให้ลองไล่ด้วย source code ที่ต้องการให้เป็นไปทีละประโยค ขาดก็แก้ไข เกินก็ตัดออก ต่อไปนี้คือ grammar ทั้งหมดตั้งแต่เริ่มต้น (ไม่มีรายละเอียดของ EXPR นะครับ)
START ::= VARIABLE_DECLARATION | BODY
VARIABLE_DECLARATION ::= { DECLARE1 } | { DECLARE2 }
DECLARE1 ::= "var" VARIABLE { "," VARIABLE } ":" TYPE
DECLARE2 ::= VARIABLE ":" TYPE
VARIABLE ::= LETTER { LETTER | DIGIT | "_" }
LETTER ::= a | b | c | ... | x | y | z | A | B | C | ... | X | Y | Z
DIGIT ::= 0 | 1 | 2 | ... | 7 | 8 | 9
TYPE ::= "int" | "float" | "double" | "char" | "string" | "bool"
BODY ::= { WHILE } | { IF }
WHILE ::= "while" "(" EXPR ")" "do" ";" STATEMENT "end" ";"
IF ::= "if" "(" EXPR ")" "then" STATEMENT [ "else" STATEMENT ] "end" ";"
STATEMENT ::= { ASSIGNMENT | WHILE | IF }
ASSIGNMENT ::= VARIABLE "=" EXPR ";"
เราสามารถปรับเปลี่ยน grammar ให้ดียิ่งขึ้น โดยเปลี่ยนการผลิตของ non-terminal ชื่อ BODY และ STATEMENT เสียใหม่ แน่นอนว่าผลของมันทำให้ grammar สามารถกำหนดค่าให้ตัวแปร (ASSIGNMENT) ได้ก่อนการใช้ while หรือ if อีกด้วย ดังนี้
BODY ::= { STATEMENT }
STATEMENT ::= ASSIGNMENT | WHILE | IF
หากเราต้องการให้ grammar สามารถประกาศตัวแปร (VARIABLE_DECLARATION) ภายใน while หรือ if ได้ ก็เพียงแต่ปรับ grammar เป็นดังนี้
STATEMENT ::=
ASSIGNMENT | WHILE | IF | VARIABLE_DECLARATION
ตัวอย่างที่ 6
Program CT414; //ประกาศฟัง์ชันชื่อ CT414
var a:int
b:real
c:bool
Begin
While( a > b + 2 ) do;
a = a - 1;
end;
sub(); //เรียกซับฟังก์ชันชื่อ sub ในในฟังก์ชันอีกที
end;
Begin //เริ่มต้นฟังก์ชัน main
CT414(); //เรียกซับฟังก์ชันชื่อ CT414
end. //สิ้นสุดฟังก์ชัน main
ตัวอย่าง source code ข้างต้นนี้ก็ไม่ยากนัก หากเพื่อนๆสามารถเข้าใจตัวอย่างก่อนหน้านี้ได้ทั้งหมด (ค่อยเป็นค่อยไปนะครับ ผมให้กำลังใจ และเข้าใจผู้ที่เริ่มต้นออกแบบทุกคน เพราะผมก็ไม่มีใครสอนเป็นพิเศษ ใช้ทั้งความจำและการสังเกตเรียนรู้ด้วยตัวเองเรื่อยมา ผิดถูกอย่างไรขออภัยด้วยครับ) เราอาจแบ่ง grammar ออกเป็นสองส่วนเสียก่อน ดังนี้ (rewrite grammar เดิม เขียนเฉพาะหลักๆนะครับ)
START ::= { FUNCTION_DECLARATION } MAIN
กำหนดให้ FUNCTION_DECLARATION คือส่วนการประกาศฟังก์ชัน เช่น Program CT414 และให้ MAIN คือส่วน main function
FUNCTION_DECLARATION ::=
"Program" VARIABLE ";" FUNCTION_BODY
FUNCTION_BODY ::= VARIABLE_DECLARATION "Begin" BODY "end" ";"
MAIN ::= "Begin" BODY "end" "."
สุดท้ายปรับ STATEMENT ให้สามารถเรียกซับฟังก์ชัน (sub function หรือฟังก์ชันย่อย) ดังต่อไปนี้จึงเป็นอันว่าแล้วเสร็จครับ
STATEMENT ::=
ASSIGNMENT | WHILE | IF | VARIABLE_DECLARATION
| CALL_FUNCTION
CALL_FUNCTION ::= VARIABLE "(" [ ARGUMENT ] ")" ";"
***หมายเหตุ
- ARGUMENT นี้หมายถึง ตัวแปรหรือค่าคงที่ (const) หรือ EXPR ที่ต้องการส่งให้กับฟังก์ชัน เพราะบางฟังก์ชันสามารถรับค่าได้ แต่บางฟังก์ชันก็ไม่สามารถรับค่าได้ ดังนั้นควรออกแบบให้ มี หรือ ไม่มี ก็ได้ จึงเลือกใช้เครื่องหมาย [ ] ครับ
หวังว่าเนื้อหาเหล่านี้คงช่วยให้เพื่อนๆสามารถออกแบบ grammar ได้เองในระดับหนึ่ง ถือว่าเป็นการเล่าสู่กันฟังแล้วกันนะครับ โอกาศหน้าค่อยเจอกันใหม่ พยายามเข้านะครับ ^^
อ่านเนื้อหาที่เกี่ยวข้อง ถัดไป
วันอังคารที่ 8 มีนาคม พ.ศ. 2554
ความหมายและหน้าที่ของคำเหล่านี้ class, static, public, void ?
คำถามนี้เป็นที่สงสัยมากสำหรับว่าที่โปรแกรมเมอร์ เรามักพบคำเหล่านี้เมื่อเริ่มศึกษาแนวคิด Object Oriented Programming (OOP) ซึ่งมีหน้าที่และความหมายพอสังเขปดังนี้ครับ
- อ่านเพิ่มเติม หลักการเชิงวัตถุ
class
- ความหมาย คำสงวนที่ระบุความเป็น abstract data type หรือชนิดข้อมูลนามธรรม
- หน้าที่ ใช้นิยามชนิดข้อมูลใหม่
- ตัวอย่าง
class Student {
}
ขณะนี้เราได้นิยามชนิดข้อมูลใหม่ ซึ่งแนวคิด OOP ให้ใช้คำสงวน class เป็นตัวระบุการนิยามดังกล่าว และตั้งชื่อมันว่า Student เป็นเหตุให้ต่อไปนี้คอมไพเลอร์จะรู้จักชนิดข้อมูลชื่อ Student และสามารถนำไปสร้างเป็นออบเจ็กต์ได้ในอนาคต
static
- ความหมาย โมดิไฟเออร์ (modifier) ลักษณะหนึ่งที่ระบุความคงที่หรือเรียกว่า อพลวัต
- หน้าที่ ระบุให้สมาชิกนั้นๆ (ที่กำหนดเป็น static แล้ว) เป็นของคลาส ไม่ใช่เป็นของออบเจ็กต์
- อ่านเพิ่มเติม บทความ Java และคำ static
- ตัวอย่าง สมาชิกเมธอดที่ไม่เป็น static และเป็น static
class Student {
public String getStudentName() { }
public static String getSchoolName() { }
}
ขณะนี้เราเพิ่มสมาชิกของคลาส Student อีกสองสมาชิกซึ่งเป็นสมาชิกประเภทเมธอด (เรียกว่า เมมเบอร์ฟังก์ชัน สำหรับภาษา C++) ชื่อ getStudentName และ getSchoolName
- getStudentName ไม่เป็น static ใช้สำหรับขอดูชื่อของออบเจ็กต์นักเรียนใดๆ (อาจได้ค่าไม่เหมือนกัน)
- getSchoolName เป็น static ใช้สำหรับขอดูชื่อโรงเรียนของทุกออบเจ็กต์ที่สร้างจากคลาส Student (ได้ค่าเหมือนกันหมด)
ในความเป็นจริงแล้ว เมื่อใช้หลักการเชิงวัตถุ (OOP) นักเรียนหนึ่งคนย่อมมีชื่อเป็นของตัวเอง เช่น แดง, ดำ, เขียว และอาจมีนักเรียนหลายคนที่ชื่อซ้ำกัน เมื่อมีใครคนหนึ่ง (สมมติเป็นบุคคลภายนอก) ถามว่า แดง, ดำ, เขียว สามคนนี้เรียนอยู่โรงเรียนชื่ออะไร แน่นอนว่าสามออบเจ็กต์ดังกล่าวเรียนอยู่โรงเรียนเดียวกัน จึงตอบว่า "โรงเรียนเด็กดีวิทยาคม" (ตัวอย่าง) ครับ
public
- ความหมาย เป็นสาธารณะ
- หน้าที่ ระบุให้คลาส, สมาชิก ใดๆถูกเข้าถึงหรือเรียกใช้งานได้อย่างอิสระ
- อ่านเพิ่มเติม ความแตกต่างของโมดิไฟเออร์, ตัวอย่างการใช้โมดิไฟเออร์
void
- ความหมาย ไม่ส่งค่ากลับ
- หน้าที่ ระบุให้สมาชิกเมธอดไม่ส่งค่ากลับไป ณ จุดเรียก (ซึ่งอาจถูกเรียก ณ main หรือเมธอดใดๆ) เมธอดนั้นจะทำงานแล้วจบไป
- ตัวอย่าง เราไปซื้อของที่ร้านสะดวกซื้อ และต้องจ่ายค่าสินค้าเป็นเงิน 150 บาท เราให้เงินเขาไป 200 บาท เขาจึงทอนเงินกลับมา 50 บาท เมื่อนำพฤติกรรมนี้มาเขียนเป็นเมธอดโดยตั้งชื่อว่า calculate เราอาจออกแบบได้ประมาณนี้
public double calculate( ราคาสินค้าทั้งหมดของลูกค้า, เงินที่ได้รับจากลูกค้า ) {
return เงินที่ได้รับจากลูกค้า - ราคาสินค้าทั้งหมดของลูกค้า;
}
เพื่อนๆจะสังเกตว่าผลลัพธ์จากการคำนวน "เงินที่ได้รับจากลูกค้า - ราคาสินค้าทั้งหมดของลูกค้า" อาจเป็นทศนิยมหรือไม่ก็ได้ เราจึงเลือกใช้ชนิดข้อมูล double เป็นชนิดข้อมูลของค่าที่ส่งออกมา (ตามตัวอย่างคือ 50.00 นั่นเอง) เรียกเมธอดที่ส่งผลลัพธ์กลับออกมานี้ว่า เมธอดที่มีการคืนค่า
พฤติกรรมบางอย่างไม่ต้องการส่งผลลัพธ์กลับออกมา เราจึงระบุชนิดการส่งกลับเป็น void เรียกว่า เมธอดที่ไม่คืนค่า เช่น เรามีกระปุกออมสินน้องหมูสดใส ดังนั้นพฤติกรรมหลักๆที่เกี่ยวข้องกับมัน ได้แก่
- การหยอดเงินใส่กระปุก ตั้งชื่อว่า put
- การเอาเงินออกจากกระปุก ตั้งชื่อว่า out
เราอาจออกแบบเมธอด put ได้ประมาณนี้
public void put( จำนวนเงิน ) {
เงินสะสมทั้งหมด = เงินสะสมทั้งหมด + จำนวนเงิน;
}
ส่วนเมธอด out เป็นลักษณะส่งผลลัพธ์กลับออกมา ดังนั้นจึงไม่ขอยกตัวอย่างอีกนะครับ
- อ่านเพิ่มเติม หลักการเชิงวัตถุ
class
- ความหมาย คำสงวนที่ระบุความเป็น abstract data type หรือชนิดข้อมูลนามธรรม
- หน้าที่ ใช้นิยามชนิดข้อมูลใหม่
- ตัวอย่าง
class Student {
}
ขณะนี้เราได้นิยามชนิดข้อมูลใหม่ ซึ่งแนวคิด OOP ให้ใช้คำสงวน class เป็นตัวระบุการนิยามดังกล่าว และตั้งชื่อมันว่า Student เป็นเหตุให้ต่อไปนี้คอมไพเลอร์จะรู้จักชนิดข้อมูลชื่อ Student และสามารถนำไปสร้างเป็นออบเจ็กต์ได้ในอนาคต
static
- ความหมาย โมดิไฟเออร์ (modifier) ลักษณะหนึ่งที่ระบุความคงที่หรือเรียกว่า อพลวัต
- หน้าที่ ระบุให้สมาชิกนั้นๆ (ที่กำหนดเป็น static แล้ว) เป็นของคลาส ไม่ใช่เป็นของออบเจ็กต์
- อ่านเพิ่มเติม บทความ Java และคำ static
- ตัวอย่าง สมาชิกเมธอดที่ไม่เป็น static และเป็น static
class Student {
public String getStudentName() { }
public static String getSchoolName() { }
}
ขณะนี้เราเพิ่มสมาชิกของคลาส Student อีกสองสมาชิกซึ่งเป็นสมาชิกประเภทเมธอด (เรียกว่า เมมเบอร์ฟังก์ชัน สำหรับภาษา C++) ชื่อ getStudentName และ getSchoolName
- getStudentName ไม่เป็น static ใช้สำหรับขอดูชื่อของออบเจ็กต์นักเรียนใดๆ (อาจได้ค่าไม่เหมือนกัน)
- getSchoolName เป็น static ใช้สำหรับขอดูชื่อโรงเรียนของทุกออบเจ็กต์ที่สร้างจากคลาส Student (ได้ค่าเหมือนกันหมด)
ในความเป็นจริงแล้ว เมื่อใช้หลักการเชิงวัตถุ (OOP) นักเรียนหนึ่งคนย่อมมีชื่อเป็นของตัวเอง เช่น แดง, ดำ, เขียว และอาจมีนักเรียนหลายคนที่ชื่อซ้ำกัน เมื่อมีใครคนหนึ่ง (สมมติเป็นบุคคลภายนอก) ถามว่า แดง, ดำ, เขียว สามคนนี้เรียนอยู่โรงเรียนชื่ออะไร แน่นอนว่าสามออบเจ็กต์ดังกล่าวเรียนอยู่โรงเรียนเดียวกัน จึงตอบว่า "โรงเรียนเด็กดีวิทยาคม" (ตัวอย่าง) ครับ
public
- ความหมาย เป็นสาธารณะ
- หน้าที่ ระบุให้คลาส, สมาชิก ใดๆถูกเข้าถึงหรือเรียกใช้งานได้อย่างอิสระ
- อ่านเพิ่มเติม ความแตกต่างของโมดิไฟเออร์, ตัวอย่างการใช้โมดิไฟเออร์
void
- ความหมาย ไม่ส่งค่ากลับ
- หน้าที่ ระบุให้สมาชิกเมธอดไม่ส่งค่ากลับไป ณ จุดเรียก (ซึ่งอาจถูกเรียก ณ main หรือเมธอดใดๆ) เมธอดนั้นจะทำงานแล้วจบไป
- ตัวอย่าง เราไปซื้อของที่ร้านสะดวกซื้อ และต้องจ่ายค่าสินค้าเป็นเงิน 150 บาท เราให้เงินเขาไป 200 บาท เขาจึงทอนเงินกลับมา 50 บาท เมื่อนำพฤติกรรมนี้มาเขียนเป็นเมธอดโดยตั้งชื่อว่า calculate เราอาจออกแบบได้ประมาณนี้
public double calculate( ราคาสินค้าทั้งหมดของลูกค้า, เงินที่ได้รับจากลูกค้า ) {
return เงินที่ได้รับจากลูกค้า - ราคาสินค้าทั้งหมดของลูกค้า;
}
เพื่อนๆจะสังเกตว่าผลลัพธ์จากการคำนวน "เงินที่ได้รับจากลูกค้า - ราคาสินค้าทั้งหมดของลูกค้า" อาจเป็นทศนิยมหรือไม่ก็ได้ เราจึงเลือกใช้ชนิดข้อมูล double เป็นชนิดข้อมูลของค่าที่ส่งออกมา (ตามตัวอย่างคือ 50.00 นั่นเอง) เรียกเมธอดที่ส่งผลลัพธ์กลับออกมานี้ว่า เมธอดที่มีการคืนค่า
พฤติกรรมบางอย่างไม่ต้องการส่งผลลัพธ์กลับออกมา เราจึงระบุชนิดการส่งกลับเป็น void เรียกว่า เมธอดที่ไม่คืนค่า เช่น เรามีกระปุกออมสินน้องหมูสดใส ดังนั้นพฤติกรรมหลักๆที่เกี่ยวข้องกับมัน ได้แก่
- การหยอดเงินใส่กระปุก ตั้งชื่อว่า put
- การเอาเงินออกจากกระปุก ตั้งชื่อว่า out
เราอาจออกแบบเมธอด put ได้ประมาณนี้
public void put( จำนวนเงิน ) {
เงินสะสมทั้งหมด = เงินสะสมทั้งหมด + จำนวนเงิน;
}
ส่วนเมธอด out เป็นลักษณะส่งผลลัพธ์กลับออกมา ดังนั้นจึงไม่ขอยกตัวอย่างอีกนะครับ
วันพฤหัสบดีที่ 3 มีนาคม พ.ศ. 2554
Compiler : Code Generator
เมื่อได้ intermediate code หรือโค้ดกลางจากกระบวนการ Parser กระบวนการ Code Generator จะสร้างผลลัพธ์สุดท้าย (target code) เป็นภาษาเครื่องหรือภาษาใดๆอย่างไรนั้น ก็ขึ้นอยู่กับข้อตกลงของอาจารย์ผู้สอนหรือตามแต่ความต้องการของผู้เขียนโปรแกรมเอง และในขณะที่ผมเรียนเรื่องนี้นั้น มีข้อตกลงร่วมกันดังนี้
ตัวอย่าง *, 2, 1, t0 จะแปลงเป็น
1. LOAD R1 2
2. MUL R1 1
3. STORE R1 t0
ตัวอย่าง /, t0, 3, t1 จะแปลงเป็น
4. LOAD R1 t0
5. DIV R1 3
6. STORE R1 t1
ตัวอย่าง +, 3, t1, t2 จะแปลงเป็น
7. LOAD R1 3
8. ADD R1 t1
9. STORE R1 t2
ตัวอย่าง -, t2, 1, t3 จะแปลงเป็น
10. LOAD R1 t2
11. SUB R1 1
12. STORE R1 t3
ตัวอย่าง =, t3, , a จะแปลงเป็น
13. LOAD R1 t3
14. STORE R1 a
จากตัวอย่างข้างต้นนี้ intermediate code ทั้งหมดสร้างจาก source code เดียวกัน ผมตั้งใจแยกมันออกเป็นตัวอย่างย่อยๆซึ่งจะสังเกตว่า เราใช้รีจิสเตอร์พักค่าหนึ่งตัวชื่อว่า R1 (แล้วแต่ข้อตกลง) และเทียบเครื่องหมาย
* เป็น MUL
/ เป็น DIV
+ เป็น ADD
- เป็น SUB
= เป็น STORE
หากมีเครื่องหมายอื่นๆ ก็แล้วแต่จะใช้คำว่าอย่างไร นอกเหนื่อจากนั้นรูปแบบก็คล้ายคลึงกันพร้อมกับใส่หมายเลขบรรทัดไปด้วย...
เพื่อนๆที่เคยเรียนภาษา assembly (ขณะที่ผมเรียนเขียนด้วย MASM32 : Microsoft assembler 32 bit) คงจำรูปแบบคำสั่งควบคุมจำพวก if หรือ while ได้บ้าง การสร้าง intermediate code อาจแตกต่างออกไปเล็กน้อย เช่น
ตัวอย่าง source code เขียนเป็น if ( a > 10 ) { a = a - 1; }
จะถูกสร้างเป็น intermediate code ดังนี้ (แล้วแต่ข้อตกลง)
>, a, 10, t0
JLE, t0, , label_end
-, a, 1, t1
=, t1, , a
LBL, , , label_end
หมายความว่า ผลการเปรียบเทียบระหว่างตัวแปร a และค่าคงที่ 10 จะได้ผลลัพธ์ไปเก็บไว้ ณ ตัวแปรชื่อ t0 (ค่านี้อาจเป็น จริง หรือ เท็จ ก็ได้) ถัดมาคำสั่ง JLE จะอ่านค่าตัวแปร t0 ...เมื่อ "a น้อยกว่าหรือเท่ากับ 10" จริง (คือ t0 มีค่าเป็นจริง) คอมพิวเตอร์จะทำคำสั่ง JLE เป็นเหตุให้กระโดดไปทำคำสั่ง ณ ตำแหน่ง LBL ที่ชื่อ label_end (ที่เขียนว่า LBL, , , label_end) ทันทีโดยข้ามสองคำสั่งต่อไปนี้
-, a, 1, t1
=, t1, , a
...แต่หากเป็นตรงกันข้ามเพราะ "a มากกว่า 10" จริง (คือ t0 มีค่าเป็นเท็จ) คอมพิวเตอร์จะไม่สนใจคำสั่ง JLE ผลคือคำสั่ง
-, a, 1, t1
=, t1, , a
จะถูกทำก่อนแล้วจึงค่อยไปทำคำสั่ง ณ ตำแหน่ง label_end เป็นลำดับ (สุดท้าย) ต่อไป...
ตัวอย่าง source code เขียนเป็น while ( a > 10 ) { a = a - 1; }
จะถูกสร้างเป็น intermediate code ดังนี้ (แล้วแต่ข้อตกลง)
LBL, , , label_begin
>, a, 10, t0
JLE, t0, , label_end
-, a, 1, t1
=, t1, , a
JMP, , , label_begin
LBL, , , label_end
intermediate code ตัวอย่างข้างต้นไม่ต่างจากตัวอย่างก่อนหน้ามากนัก เพียงแต่เพิ่มการวนรอบ (JMP) กลับไปตรวจสอบเงื่อนไข a > 10 นั้นอยู่เรื่อย จนกระทั่งเงื่อนไขดังกล่าวจะเป็นเท็จจึงยุติลง... (หรือกล่าวว่าทำคำสั่งถัดไป ณ ตำแหน่ง label_end (ที่เขียนว่า LBL, , , label_end))
อัลกอริทึมที่ใช้สำหรับกระบวนการ Code Generator มีอยู่หลายวิธี (ขอภัย เพราะผมลืมไปเกือบหมดแล้ว) เมื่อยึดเอา intermediate code จากตัวอย่างล่าสุดข้างต้น ผมเลือกใช้วิธีการที่มีรูปแบบที่แบ่งออกเป็นสองขั้นตอนใหญ่ๆ ดังนี้
- ขั้นตอนแรก บันทึกชื่อของตำแหน่ง (label) จากคำสั่ง LBL เท่านั้น โดยนับบรรทัดไปพร้อมๆกัน เริ่มจาก
---- ให้ตัวแปรชื่อ countLine คอยนับจำนวนบรรทัดที่จะถูกแปลงเป็นโค้ดเป้าหมาย เริ่มต้นค่าเป็นหนึ่ง
---- เมื่ออ่านมาพบ LBL, , , label_begin ให้บันทึกชื่อ label_begin ไว้พร้อมกับระบุหมายเลขบรรทัดไว้เป็น 1
---- เมื่ออ่านมาพบ >, a, 10, t0 ค่าของ countLine จะเพิ่มขึ้นอีก 3 รวมแล้วเท่ากับ 4 (เลขสามนั้นมาจาก intermediate code นี้หนึ่งคำสั่ง ถูกแปลงเป็นโค้ดเป้าหมายจำนวนสามคำสั่ง (หรือสามบรรทัด) นั้นเอง)
---- เมื่ออ่านมาพบ JLE, t0, , label_end ค่าของ countLine จะเพิ่มขึ้นอีก 1 รวมแล้วเท่ากับ 5 (เพราะมันจะถูกแปลงเป็นโค้ดเป้าหมายเพียงหนึ่งคำสั่ง)
---- เมื่ออ่านมาพบ -, a, 1, t1 ค่าของ countLine จะเพิ่มขึ้นอีก 3 รวมแล้วเท่ากับ 8
---- เมื่ออ่านมาพบ =, t1, , a ค่าของ countLine จะเพิ่มขึ้นอีก 2 รวมแล้วเท่ากับ 10
---- เมื่ออ่านมาพบ JMP, , , label_begin ค่าของ countLine จะเพิ่มขึ้นอีก 1 รวมแล้วเท่ากับ 11
---- เมื่ออ่านมาพบ LBL, , , label_end ให้บันทึกชื่อ label_end ไว้พร้อมกับระบุหมายเลขบรรทัดไว้เป็น 11
- ขั้นตอนที่สอง อ่าน intermediate code ใหม่อีกรอบ โดยไม่สนใจคำสั่ง LBL แต่กลับสนใจชื่อ label ของคำสั่ง jump ต่างๆแทน (ในที่นี้คำสั่ง jump ได้แก่ JLE และ JMP)
---- ตั้งค่าตัวแปร countLine เป็นหนึ่งอีกครั้ง
---- เมื่ออ่านมาพบ LBL, , , label_begin ให้เลยผ่านไป
---- เมื่ออ่านมาพบ >, a, 10, t0 ให้แปลงเป็นโค้ดเป้าหมาย พร้อมกับระบุหมายเลขบรรทัด
1. LOAD R1 a
2. GT R1 10
3. STORE R1 t0
---- เมื่ออ่านมาพบ JLE, t0, , label_end ให้นำชื่อ label_end เทียบหาชื่อที่ตรงกันจากชื่อ label ทั้งหมดที่ได้บันทึกไว้ในขั้นตอนแรก แล้วนำหมายเลขบรรทัดที่บันทึกไว้พร้อมกันแปลงเป็นโค้ดเป้าหมาย
4. JLE 11
---- เมื่ออ่านมาพบ -, a, 1, t1
5. LOAD R1 a
6. SUB R1 1
7.STORE R1 t1
---- เมื่ออ่านมาพบ =, t1, , a
8. LOAD R1 t1
9. STORE R1 a
---- เมื่ออ่านมาพบ JMP, , , label_begin
10. JMP 1
ดาวน์โหลดโปรแกรม Compiler ที่เขียนด้วย Grammar 3 (Run ด้วย NetBeans IDE) ซึ่งเพิ่มเติมกระบวนการ Code Generator
ทดสอบ
รูปด้านล่างนี้แสดงผลการทดสอบ การสร้าง target code โดยใช้ intermediate code ตามตัวอย่างล่าสุดข้างต้น (ของบทความหน้านี้) พร้อมผลลัพธ์ แต่ถ้าเพื่อนๆต้องการให้แสดงผลลัพธ์จาก intermediate code ปกติของ grammar 3 ให้เพื่อนๆยกเลิก comment บรรทัดที่ 36 และใส่ comment บรรทัดที่ 35 แทนครับ

ผลลัพธ์

อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า
ตัวอย่าง *, 2, 1, t0 จะแปลงเป็น
1. LOAD R1 2
2. MUL R1 1
3. STORE R1 t0
ตัวอย่าง /, t0, 3, t1 จะแปลงเป็น
4. LOAD R1 t0
5. DIV R1 3
6. STORE R1 t1
ตัวอย่าง +, 3, t1, t2 จะแปลงเป็น
7. LOAD R1 3
8. ADD R1 t1
9. STORE R1 t2
ตัวอย่าง -, t2, 1, t3 จะแปลงเป็น
10. LOAD R1 t2
11. SUB R1 1
12. STORE R1 t3
ตัวอย่าง =, t3, , a จะแปลงเป็น
13. LOAD R1 t3
14. STORE R1 a
จากตัวอย่างข้างต้นนี้ intermediate code ทั้งหมดสร้างจาก source code เดียวกัน ผมตั้งใจแยกมันออกเป็นตัวอย่างย่อยๆซึ่งจะสังเกตว่า เราใช้รีจิสเตอร์พักค่าหนึ่งตัวชื่อว่า R1 (แล้วแต่ข้อตกลง) และเทียบเครื่องหมาย
* เป็น MUL
/ เป็น DIV
+ เป็น ADD
- เป็น SUB
= เป็น STORE
หากมีเครื่องหมายอื่นๆ ก็แล้วแต่จะใช้คำว่าอย่างไร นอกเหนื่อจากนั้นรูปแบบก็คล้ายคลึงกันพร้อมกับใส่หมายเลขบรรทัดไปด้วย...
เพื่อนๆที่เคยเรียนภาษา assembly (ขณะที่ผมเรียนเขียนด้วย MASM32 : Microsoft assembler 32 bit) คงจำรูปแบบคำสั่งควบคุมจำพวก if หรือ while ได้บ้าง การสร้าง intermediate code อาจแตกต่างออกไปเล็กน้อย เช่น
ตัวอย่าง source code เขียนเป็น if ( a > 10 ) { a = a - 1; }
จะถูกสร้างเป็น intermediate code ดังนี้ (แล้วแต่ข้อตกลง)
>, a, 10, t0
JLE, t0, , label_end
-, a, 1, t1
=, t1, , a
LBL, , , label_end
หมายความว่า ผลการเปรียบเทียบระหว่างตัวแปร a และค่าคงที่ 10 จะได้ผลลัพธ์ไปเก็บไว้ ณ ตัวแปรชื่อ t0 (ค่านี้อาจเป็น จริง หรือ เท็จ ก็ได้) ถัดมาคำสั่ง JLE จะอ่านค่าตัวแปร t0 ...เมื่อ "a น้อยกว่าหรือเท่ากับ 10" จริง (คือ t0 มีค่าเป็นจริง) คอมพิวเตอร์จะทำคำสั่ง JLE เป็นเหตุให้กระโดดไปทำคำสั่ง ณ ตำแหน่ง LBL ที่ชื่อ label_end (ที่เขียนว่า LBL, , , label_end) ทันทีโดยข้ามสองคำสั่งต่อไปนี้
-, a, 1, t1
=, t1, , a
...แต่หากเป็นตรงกันข้ามเพราะ "a มากกว่า 10" จริง (คือ t0 มีค่าเป็นเท็จ) คอมพิวเตอร์จะไม่สนใจคำสั่ง JLE ผลคือคำสั่ง
-, a, 1, t1
=, t1, , a
จะถูกทำก่อนแล้วจึงค่อยไปทำคำสั่ง ณ ตำแหน่ง label_end เป็นลำดับ (สุดท้าย) ต่อไป...
ตัวอย่าง source code เขียนเป็น while ( a > 10 ) { a = a - 1; }
จะถูกสร้างเป็น intermediate code ดังนี้ (แล้วแต่ข้อตกลง)
LBL, , , label_begin
>, a, 10, t0
JLE, t0, , label_end
-, a, 1, t1
=, t1, , a
JMP, , , label_begin
LBL, , , label_end
intermediate code ตัวอย่างข้างต้นไม่ต่างจากตัวอย่างก่อนหน้ามากนัก เพียงแต่เพิ่มการวนรอบ (JMP) กลับไปตรวจสอบเงื่อนไข a > 10 นั้นอยู่เรื่อย จนกระทั่งเงื่อนไขดังกล่าวจะเป็นเท็จจึงยุติลง... (หรือกล่าวว่าทำคำสั่งถัดไป ณ ตำแหน่ง label_end (ที่เขียนว่า LBL, , , label_end))
อัลกอริทึมที่ใช้สำหรับกระบวนการ Code Generator มีอยู่หลายวิธี (ขอภัย เพราะผมลืมไปเกือบหมดแล้ว) เมื่อยึดเอา intermediate code จากตัวอย่างล่าสุดข้างต้น ผมเลือกใช้วิธีการที่มีรูปแบบที่แบ่งออกเป็นสองขั้นตอนใหญ่ๆ ดังนี้
- ขั้นตอนแรก บันทึกชื่อของตำแหน่ง (label) จากคำสั่ง LBL เท่านั้น โดยนับบรรทัดไปพร้อมๆกัน เริ่มจาก
---- ให้ตัวแปรชื่อ countLine คอยนับจำนวนบรรทัดที่จะถูกแปลงเป็นโค้ดเป้าหมาย เริ่มต้นค่าเป็นหนึ่ง
---- เมื่ออ่านมาพบ LBL, , , label_begin ให้บันทึกชื่อ label_begin ไว้พร้อมกับระบุหมายเลขบรรทัดไว้เป็น 1
---- เมื่ออ่านมาพบ >, a, 10, t0 ค่าของ countLine จะเพิ่มขึ้นอีก 3 รวมแล้วเท่ากับ 4 (เลขสามนั้นมาจาก intermediate code นี้หนึ่งคำสั่ง ถูกแปลงเป็นโค้ดเป้าหมายจำนวนสามคำสั่ง (หรือสามบรรทัด) นั้นเอง)
---- เมื่ออ่านมาพบ JLE, t0, , label_end ค่าของ countLine จะเพิ่มขึ้นอีก 1 รวมแล้วเท่ากับ 5 (เพราะมันจะถูกแปลงเป็นโค้ดเป้าหมายเพียงหนึ่งคำสั่ง)
---- เมื่ออ่านมาพบ -, a, 1, t1 ค่าของ countLine จะเพิ่มขึ้นอีก 3 รวมแล้วเท่ากับ 8
---- เมื่ออ่านมาพบ =, t1, , a ค่าของ countLine จะเพิ่มขึ้นอีก 2 รวมแล้วเท่ากับ 10
---- เมื่ออ่านมาพบ JMP, , , label_begin ค่าของ countLine จะเพิ่มขึ้นอีก 1 รวมแล้วเท่ากับ 11
---- เมื่ออ่านมาพบ LBL, , , label_end ให้บันทึกชื่อ label_end ไว้พร้อมกับระบุหมายเลขบรรทัดไว้เป็น 11
- ขั้นตอนที่สอง อ่าน intermediate code ใหม่อีกรอบ โดยไม่สนใจคำสั่ง LBL แต่กลับสนใจชื่อ label ของคำสั่ง jump ต่างๆแทน (ในที่นี้คำสั่ง jump ได้แก่ JLE และ JMP)
---- ตั้งค่าตัวแปร countLine เป็นหนึ่งอีกครั้ง
---- เมื่ออ่านมาพบ LBL, , , label_begin ให้เลยผ่านไป
---- เมื่ออ่านมาพบ >, a, 10, t0 ให้แปลงเป็นโค้ดเป้าหมาย พร้อมกับระบุหมายเลขบรรทัด
1. LOAD R1 a
2. GT R1 10
3. STORE R1 t0
---- เมื่ออ่านมาพบ JLE, t0, , label_end ให้นำชื่อ label_end เทียบหาชื่อที่ตรงกันจากชื่อ label ทั้งหมดที่ได้บันทึกไว้ในขั้นตอนแรก แล้วนำหมายเลขบรรทัดที่บันทึกไว้พร้อมกันแปลงเป็นโค้ดเป้าหมาย
4. JLE 11
---- เมื่ออ่านมาพบ -, a, 1, t1
5. LOAD R1 a
6. SUB R1 1
7.STORE R1 t1
---- เมื่ออ่านมาพบ =, t1, , a
8. LOAD R1 t1
9. STORE R1 a
---- เมื่ออ่านมาพบ JMP, , , label_begin
10. JMP 1
ดาวน์โหลดโปรแกรม Compiler ที่เขียนด้วย Grammar 3 (Run ด้วย NetBeans IDE) ซึ่งเพิ่มเติมกระบวนการ Code Generator
ทดสอบ
รูปด้านล่างนี้แสดงผลการทดสอบ การสร้าง target code โดยใช้ intermediate code ตามตัวอย่างล่าสุดข้างต้น (ของบทความหน้านี้) พร้อมผลลัพธ์ แต่ถ้าเพื่อนๆต้องการให้แสดงผลลัพธ์จาก intermediate code ปกติของ grammar 3 ให้เพื่อนๆยกเลิก comment บรรทัดที่ 36 และใส่ comment บรรทัดที่ 35 แทนครับ

ผลลัพธ์

อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า
วันจันทร์ที่ 28 กุมภาพันธ์ พ.ศ. 2554
Compiler : Intermediate Code
เรื่องของโค้ดกลางหรือภาษากลาง (Intermediate Code) นี้ถูกใช้กับคอมไพเลอร์แทบทุกภาษา โดยเป็นที่ตกลงกันว่าต้องมีรูปแบบ (ไวยากรณ์) อย่างโน้นอย่างนี่ สำหรับเพื่อนๆที่ต้องส่งงานชิ้นนี้ให้กับอาจารย์ผู้สอน จึงต้องตกลงกันกับอาจารย์ผู้สอนว่าจะให้โปรแกรมคอมไพเลอร์ที่เขียนขึ้นนี้สร้างโค้ดกลางขึ้นมาในรูปแบบใด...
เกร็ดเล็กเกร็ดน้อย : โปรแกรมเมอร์ภาษา Basic.NET, C++.NET, C#.NET ฯลฯ ภายหลังคอมไพล์โค้ดต้นฉบับ (source code) จะได้โค้ดกลางที่เรียกว่า MSIL เหมือนกันทั้งหมด เป็นเหตุให้โครงการ (project) ที่พัฒนาด้วย .NET แม้เขียนจากภาษาที่หลากหลายยังสามารถทำงานร่วมกันได้เป็นอย่างดี หรือ bytecode ของภาษา Java ก็เป็นจัดเป็นโค้ดกลางเช่นกัน
เป็นที่ตกลง (ณ ขณะที่ผมเรียน) ให้รูปแบบของโค้ดกลางเป็นดังนี้
operator, operand1, operand2, result
โดยเฉพาะ result หมายถึง ตัวแปรชื่อใดๆก็ได้สำหรับเก็บผลลัพธ์ และตามตัวอย่างด้านล่างนี้จะใช้ชื่อเป็น t0, t1, t2, ... ไปเรื่อยๆครับ
ตัวอย่าง 3 + 2 - 1 เมื่อความสำคัญการบวกและลบเท่ากัน
+ , 3 , 2 , t0
- , t0, 1, t1
ตัวอย่าง 3 + 2 * 1 เมื่อความสำคัญการคูณมากกว่าการบวก
* , 2 , 1 , t0
+ , 3 , t0 , t1
ตัวอย่าง a = b % 10 * 5 เมื่อความสำคัญ % เท่ากับ * และมันทั้งสองมากกว่า =
% , b , 10 , t0
* , t0 , 5 , t1
= , t1 , , a
ตัวอย่าง a != b || c - ( d && f ) * 3 เมื่อความสำคัญ ( ) สูงสุด
&& , d , f , t0
* , t0 , 3 , t1
- , c , t1 , t2
|| , b , t2 , t3
!= , a , t3 , t4
...และอื่นๆ ศึกษาเพิ่มเติมในหนังสือและชั้นเรียนนะครับ
เราจะอาศัยโปรแกรมคอมไพล์เลอร์ที่ชื่อ Grammar2 จากหัวข้อที่แล้วมาประยุกต์สร้าง intermediate code สำหรับการบวก, การลบ การคูณและการหารขึ้น โดยให้ชื่อว่า Grammar3 มีรูปแบบดังนี้
<S> -> <AddSubDigit>
<AddSubDigit> -> <MulDivDigit> <AddSubDigit2>
<AddSubDigit2> -> <AddSubSymbol> <MulDivDigit> <AddSubDigit2> | empty
<MulDivDigit> -> <Digit> <MulDivDigit2>
<MulDivDigit2> -> <MulDivSymbol> <Digit> <MulDivDigit2> | empty
<AddSubSymbol> -> "+" | "-"
<MulDivSymbol> -> "*" | "/"
<Digit> -> "1" | "2" | "3"
- จากชื่อ AddDigit เป็น AddSubDigit สำหรับการบวกและการลบ
- จากชื่อ AddDigit2 เป็น AddSubDigit2 สำหรับการบวกและการลบ
- เพิ่ม MulDivDigit สำหรับการคูณและการหาร
- เพิ่ม MulDivDigit2 สำหรับการคูณและการหาร
- เพิ่ม non-terminal ชื่อ AddSubSymbol สำหรับเลือก terminal เป็น + หรือ -
- เพิ่ม non-terminal ชื่อ MulDivSymbol สำหรับเลือก terminal เป็น * หรือ /
- ลำดับความสำคัญการคูณและการหารเท่ากันจากซ้ายไปขวา
- ลำดับความสำคัญการบวกและการลบเท่ากันจากซ้ายไปขวา
- ลำดับความสำคัญการคูณและการหาร มากกว่า การบวกและการลบ
- ดาวน์โหลดโปรแกรม Compiler ที่เขียนด้วย Grammar 3 (Run ด้วย NetBeans IDE)
รูปประกอบ : source code ที่ใช้ทดสอบ
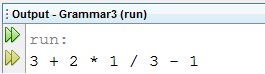
รูปประกอบ : ผลลัพธ์

อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า หรือ ถัดไป
เกร็ดเล็กเกร็ดน้อย : โปรแกรมเมอร์ภาษา Basic.NET, C++.NET, C#.NET ฯลฯ ภายหลังคอมไพล์โค้ดต้นฉบับ (source code) จะได้โค้ดกลางที่เรียกว่า MSIL เหมือนกันทั้งหมด เป็นเหตุให้โครงการ (project) ที่พัฒนาด้วย .NET แม้เขียนจากภาษาที่หลากหลายยังสามารถทำงานร่วมกันได้เป็นอย่างดี หรือ bytecode ของภาษา Java ก็เป็นจัดเป็นโค้ดกลางเช่นกัน
เป็นที่ตกลง (ณ ขณะที่ผมเรียน) ให้รูปแบบของโค้ดกลางเป็นดังนี้
โดยเฉพาะ result หมายถึง ตัวแปรชื่อใดๆก็ได้สำหรับเก็บผลลัพธ์ และตามตัวอย่างด้านล่างนี้จะใช้ชื่อเป็น t0, t1, t2, ... ไปเรื่อยๆครับ
ตัวอย่าง 3 + 2 - 1 เมื่อความสำคัญการบวกและลบเท่ากัน
+ , 3 , 2 , t0
- , t0, 1, t1
ตัวอย่าง 3 + 2 * 1 เมื่อความสำคัญการคูณมากกว่าการบวก
* , 2 , 1 , t0
+ , 3 , t0 , t1
ตัวอย่าง a = b % 10 * 5 เมื่อความสำคัญ % เท่ากับ * และมันทั้งสองมากกว่า =
% , b , 10 , t0
* , t0 , 5 , t1
= , t1 , , a
ตัวอย่าง a != b || c - ( d && f ) * 3 เมื่อความสำคัญ ( ) สูงสุด
&& , d , f , t0
* , t0 , 3 , t1
- , c , t1 , t2
|| , b , t2 , t3
!= , a , t3 , t4
...และอื่นๆ ศึกษาเพิ่มเติมในหนังสือและชั้นเรียนนะครับ
เราจะอาศัยโปรแกรมคอมไพล์เลอร์ที่ชื่อ Grammar2 จากหัวข้อที่แล้วมาประยุกต์สร้าง intermediate code สำหรับการบวก, การลบ การคูณและการหารขึ้น โดยให้ชื่อว่า Grammar3 มีรูปแบบดังนี้
<S> -> <AddSubDigit>
<AddSubDigit> -> <MulDivDigit> <AddSubDigit2>
<AddSubDigit2> -> <AddSubSymbol> <MulDivDigit> <AddSubDigit2> | empty
<MulDivDigit> -> <Digit> <MulDivDigit2>
<MulDivDigit2> -> <MulDivSymbol> <Digit> <MulDivDigit2> | empty
<AddSubSymbol> -> "+" | "-"
<MulDivSymbol> -> "*" | "/"
<Digit> -> "1" | "2" | "3"
- จากชื่อ AddDigit เป็น AddSubDigit สำหรับการบวกและการลบ
- จากชื่อ AddDigit2 เป็น AddSubDigit2 สำหรับการบวกและการลบ
- เพิ่ม MulDivDigit สำหรับการคูณและการหาร
- เพิ่ม MulDivDigit2 สำหรับการคูณและการหาร
- เพิ่ม non-terminal ชื่อ AddSubSymbol สำหรับเลือก terminal เป็น + หรือ -
- เพิ่ม non-terminal ชื่อ MulDivSymbol สำหรับเลือก terminal เป็น * หรือ /
- ลำดับความสำคัญการคูณและการหารเท่ากันจากซ้ายไปขวา
- ลำดับความสำคัญการบวกและการลบเท่ากันจากซ้ายไปขวา
- ลำดับความสำคัญการคูณและการหาร มากกว่า การบวกและการลบ
- ดาวน์โหลดโปรแกรม Compiler ที่เขียนด้วย Grammar 3 (Run ด้วย NetBeans IDE)
รูปประกอบ : source code ที่ใช้ทดสอบ

รูปประกอบ : ผลลัพธ์

อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า หรือ ถัดไป
วันพฤหัสบดีที่ 10 กุมภาพันธ์ พ.ศ. 2554
Windows Forms Application (ภาษา C#)
...นานแล้วที่ผมไม่ได้กลับมาเขียน blogs อีก เนื่องจากงานภายนอกที่มากมายและความสนใจต่อ blogs น้อยลง (ขอโทษ) อย่างไรเมื่อเห็น comment ของเพื่อนๆจึงเกิดกำลังใจที่จะเขียนต่อไป
โอกาสนี้จึงขอเริ่มการเขียนภาษา C# ในลักษณะที่มองเห็นได้ (visual) ผ่านรูปแบบ Windows Forms Application ครับ
สร้างโปรเจกต์ชื่อ BookShop
โปรเจกต์นี้จะจำลองร้านขายหนังสือ โดยแบ่งออกเป็นสองส่วน ได้แก่
- หน้าร้าน
- หลังร้าน
เราเริ่มจากส่วนหลังร้านก่อน โดยสมมติให้พนักงานประจำร้านสามารถเรียกดู, เพิ่ม, แก้ไข หรือลบข้อมูลเกี่ยวกับสินค้าในร้านได้
***หมายเหตุ นับจากนี้ผมจะพยายามประยุกต์คำถามต่างๆของเพื่อนๆที่มีต่อภาษา C# ที่เราเรียนรู้ร่วมกันมา ดังนั้นแต่ละตัวอย่างนับจากนี้จะผูกติดต่อกันไปเรื่อยๆจนกว่าโปรเจกต์ดังกล่าวจะเป็นอันสิ้นสุดลง อาจยากไปบ้างแต่ขอให้เพื่อนๆอดทนและทำตามแต่ละขั้นตอนไปพร้อมๆกัน ผมจะพยายามอธิบายแต่ละส่วนเต็มความสามารถครับ
- เปิด Microsoft Visual Studio (หากเวอร์ชั่นของพวกเราต่างกัน ไม่ว่าจะเป็น 2005, 2008 หรือ 2010 อย่างไรคำสั่งก็ยังไม่แตกต่างมากครับ)
- เลือกเมนู File -> New -> Project...
- เลือก Templates เป็น Visual C#
- เลือกรูปแบบ Windows Forms Application
- ตั้งชื่อโปรเจกต์เป็น BookShop และผมเลือกไม่สร้าง solution ครับ
จะปรากฎหน้าต่าง Form1.cs [Design]
- ให้ทดลองกด Ctrl + F5 หรือเลือกเมนู Debug -> Start Without Debugging
***เกร็ดเล็กเกร็ดน้อย สลับการใช้งานโหมด Layout ระหว่าง SnapLines และ SnapToGrid
- เลือกเมนู Tools -> Options
- เลือกหมวด Windows Forms Designer -> General
- มองไปทางด้านขวาเลือกหัวข้อ LayoutMode เป็น SnapToGrid
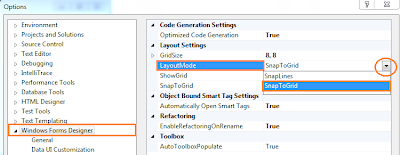
...จากความรู้เรื่องพรอเพอร์ตี้ที่ผ่านมา เพื่อนๆสามารถปรับเปลี่ยนคุณสมบัติของ form ได้ตามต้องการ
- กดปุ่มรูป ซึ่งอาจอยู่ด้านบนมุมขวา หรือเลือกเมนู View -> Properties Window
ซึ่งอาจอยู่ด้านบนมุมขวา หรือเลือกเมนู View -> Properties Window
- มองหาพรอเพอร์ตี้ชื่อ Text แล้วเปลี่ยนเป็นข้อความ หลังร้าน
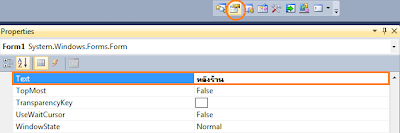
***หมายเหตุ พรอเพอร์ตี้อื่นๆให้เพื่อนๆทดลองปรับเปลี่ยนตามใจชอบ แล้วสังเกตผลลัพธ์ที่เกิดขึ้น จะทำให้เรียนรู้ไวยิ่งขึ้นครับ
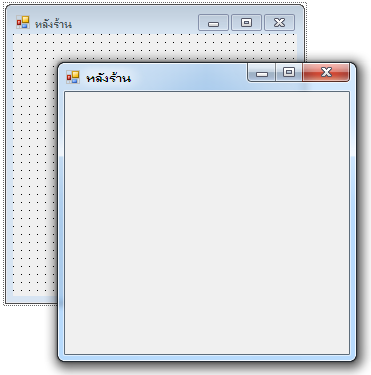
อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า หรือ ถัดไป
โอกาสนี้จึงขอเริ่มการเขียนภาษา C# ในลักษณะที่มองเห็นได้ (visual) ผ่านรูปแบบ Windows Forms Application ครับ
สร้างโปรเจกต์ชื่อ BookShop
โปรเจกต์นี้จะจำลองร้านขายหนังสือ โดยแบ่งออกเป็นสองส่วน ได้แก่
- หน้าร้าน
- หลังร้าน
เราเริ่มจากส่วนหลังร้านก่อน โดยสมมติให้พนักงานประจำร้านสามารถเรียกดู, เพิ่ม, แก้ไข หรือลบข้อมูลเกี่ยวกับสินค้าในร้านได้
***หมายเหตุ นับจากนี้ผมจะพยายามประยุกต์คำถามต่างๆของเพื่อนๆที่มีต่อภาษา C# ที่เราเรียนรู้ร่วมกันมา ดังนั้นแต่ละตัวอย่างนับจากนี้จะผูกติดต่อกันไปเรื่อยๆจนกว่าโปรเจกต์ดังกล่าวจะเป็นอันสิ้นสุดลง อาจยากไปบ้างแต่ขอให้เพื่อนๆอดทนและทำตามแต่ละขั้นตอนไปพร้อมๆกัน ผมจะพยายามอธิบายแต่ละส่วนเต็มความสามารถครับ
- เปิด Microsoft Visual Studio (หากเวอร์ชั่นของพวกเราต่างกัน ไม่ว่าจะเป็น 2005, 2008 หรือ 2010 อย่างไรคำสั่งก็ยังไม่แตกต่างมากครับ)
- เลือกเมนู File -> New -> Project...
- เลือก Templates เป็น Visual C#
- เลือกรูปแบบ Windows Forms Application
- ตั้งชื่อโปรเจกต์เป็น BookShop และผมเลือกไม่สร้าง solution ครับ

จะปรากฎหน้าต่าง Form1.cs [Design]
- ให้ทดลองกด Ctrl + F5 หรือเลือกเมนู Debug -> Start Without Debugging

***เกร็ดเล็กเกร็ดน้อย สลับการใช้งานโหมด Layout ระหว่าง SnapLines และ SnapToGrid
- เลือกเมนู Tools -> Options
- เลือกหมวด Windows Forms Designer -> General
- มองไปทางด้านขวาเลือกหัวข้อ LayoutMode เป็น SnapToGrid

...จากความรู้เรื่องพรอเพอร์ตี้ที่ผ่านมา เพื่อนๆสามารถปรับเปลี่ยนคุณสมบัติของ form ได้ตามต้องการ
- กดปุ่มรูป
 ซึ่งอาจอยู่ด้านบนมุมขวา หรือเลือกเมนู View -> Properties Window
ซึ่งอาจอยู่ด้านบนมุมขวา หรือเลือกเมนู View -> Properties Window- มองหาพรอเพอร์ตี้ชื่อ Text แล้วเปลี่ยนเป็นข้อความ หลังร้าน

***หมายเหตุ พรอเพอร์ตี้อื่นๆให้เพื่อนๆทดลองปรับเปลี่ยนตามใจชอบ แล้วสังเกตผลลัพธ์ที่เกิดขึ้น จะทำให้เรียนรู้ไวยิ่งขึ้นครับ

อ่านเนื้อหาที่เกี่ยวข้อง ก่อนหน้า หรือ ถัดไป
สมัครสมาชิก:
บทความ (Atom)